Complete eSignature Word Simple
Make the most out of your eSignature workflows with airSlate SignNow
Extensive suite of eSignature tools
Robust integration and API capabilities
Advanced security and compliance
Various collaboration tools
Enjoyable and stress-free signing experience
Extensive support
How To Add Sign in eSignPay

Keep your eSignature workflows on track
Our user reviews speak for themselves









Award-winning eSignature solution




Complete eSignature Word Simple. Check out one of the most customer-helpful knowledge of airSlate SignNow. Handle all of your document processing and revealing process electronically. Change from hand-held, paper-dependent and erroneous workflows to computerized, electronic and perfect. It is simple to create, deliver and indication any paperwork on any gadget everywhere. Ensure that your airSlate SignNow enterprise situations don't slide over the top.
Find out how to Complete eSignature Word Simple. Stick to the simple manual to start:
- Create your airSlate SignNow account in clicks or sign in together with your Facebook or Google bank account.
- Take pleasure in the 30-day time free trial or select a rates program that's great for you.
- Find any authorized web template, build on the web fillable types and talk about them firmly.
- Use advanced characteristics to Complete eSignature Word Simple.
- Signal, personalize putting your signature on buy and collect in-man or woman signatures 10 times faster.
- Establish auto reminders and acquire notices at every step.
Moving your duties into airSlate SignNow is uncomplicated. What follows is an easy approach to Complete eSignature Word Simple, together with suggestions to maintain your colleagues and partners for greater collaboration. Inspire your employees with all the very best instruments to stay on top of organization processes. Increase productivity and range your organization faster.
How it works
Rate your experience
-
Best ROI. Our customers achieve an average 7x ROI within the first six months.
-
Scales with your use cases. From SMBs to mid-market, airSlate SignNow delivers results for businesses of all sizes.
-
Intuitive UI and API. Sign and send documents from your apps in minutes.
A smarter way to work: —how to industry sign banking integrate

How to sign and fill out a document online
Document management isn't an easy task. The only thing that makes working with documents simple in today's world, is a comprehensive workflow solution. Signing and editing documents, and filling out forms is a simple task for those who utilize eSignature services. Businesses that have found reliable solutions to functionality e signature complete word simple don't need to spend their valuable time and effort on routine and monotonous actions.
Use airSlate SignNow and functionality e signature complete word simple online hassle-free today:
- Create your airSlate SignNow profile or use your Google account to sign up.
- Upload a document.
- Work on it; sign it, edit it and add fillable fields to it.
- Select Done and export the sample: send it or save it to your device.
As you can see, there is nothing complicated about filling out and signing documents when you have the right tool. Our advanced editor is great for getting forms and contracts exactly how you want/need them. It has a user-friendly interface and full comprehensibility, providing you with complete control. Create an account right now and start increasing your eSign workflows with powerful tools to functionality e signature complete word simple on the web.
How to sign and complete documents in Google Chrome
Google Chrome can solve more problems than you can even imagine using powerful tools called 'extensions'. There are thousands you can easily add right to your browser called ‘add-ons’ and each has a unique ability to enhance your workflow. For example, functionality e signature complete word simple and edit docs with airSlate SignNow.
To add the airSlate SignNow extension for Google Chrome, follow the next steps:
- Go to Chrome Web Store, type in 'airSlate SignNow' and press enter. Then, hit the Add to Chrome button and wait a few seconds while it installs.
- Find a document that you need to sign, right click it and select airSlate SignNow.
- Edit and sign your document.
- Save your new file to your account, the cloud or your device.
Using this extension, you prevent wasting time and effort on dull assignments like saving the document and importing it to an electronic signature solution’s library. Everything is easily accessible, so you can quickly and conveniently functionality e signature complete word simple.
How to sign docs in Gmail
Gmail is probably the most popular mail service utilized by millions of people all across the world. Most likely, you and your clients also use it for personal and business communication. However, the question on a lot of people’s minds is: how can I functionality e signature complete word simple a document that was emailed to me in Gmail? Something amazing has happened that is changing the way business is done. airSlate SignNow and Google have created an impactful add on that lets you functionality e signature complete word simple, edit, set signing orders and much more without leaving your inbox.
Boost your workflow with a revolutionary Gmail add on from airSlate SignNow:
- Find the airSlate SignNow extension for Gmail from the Chrome Web Store and install it.
- Go to your inbox and open the email that contains the attachment that needs signing.
- Click the airSlate SignNow icon found in the right-hand toolbar.
- Work on your document; edit it, add fillable fields and even sign it yourself.
- Click Done and email the executed document to the respective parties.
With helpful extensions, manipulations to functionality e signature complete word simple various forms are easy. The less time you spend switching browser windows, opening several accounts and scrolling through your internal records searching for a template is a lot more time to you for other important duties.
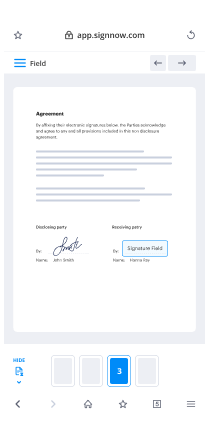

How to safely sign documents in a mobile browser
Are you one of the business professionals who’ve decided to go 100% mobile in 2020? If yes, then you really need to make sure you have an effective solution for managing your document workflows from your phone, e.g., functionality e signature complete word simple, and edit forms in real time. airSlate SignNow has one of the most exciting tools for mobile users. A web-based application. functionality e signature complete word simple instantly from anywhere.
How to securely sign documents in a mobile browser
- Create an airSlate SignNow profile or log in using any web browser on your smartphone or tablet.
- Upload a document from the cloud or internal storage.
- Fill out and sign the sample.
- Tap Done.
- Do anything you need right from your account.
airSlate SignNow takes pride in protecting customer data. Be confident that anything you upload to your account is secured with industry-leading encryption. Automated logging out will protect your profile from unwanted access. functionality e signature complete word simple from your phone or your friend’s mobile phone. Security is vital to our success and yours to mobile workflows.
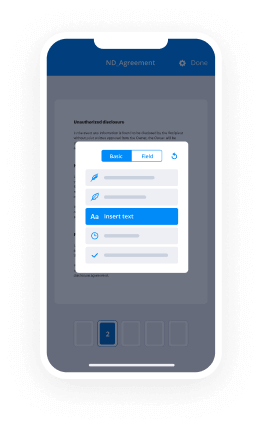

How to sign a PDF document on an iPhone or iPad
The iPhone and iPad are powerful gadgets that allow you to work not only from the office but from anywhere in the world. For example, you can finalize and sign documents or functionality e signature complete word simple directly on your phone or tablet at the office, at home or even on the beach. iOS offers native features like the Markup tool, though it’s limiting and doesn’t have any automation. Though the airSlate SignNow application for Apple is packed with everything you need for upgrading your document workflow. functionality e signature complete word simple, fill out and sign forms on your phone in minutes.
How to sign a PDF on an iPhone
- Go to the AppStore, find the airSlate SignNow app and download it.
- Open the application, log in or create a profile.
- Select + to upload a document from your device or import it from the cloud.
- Fill out the sample and create your electronic signature.
- Click Done to finish the editing and signing session.
When you have this application installed, you don't need to upload a file each time you get it for signing. Just open the document on your iPhone, click the Share icon and select the Sign with airSlate SignNow button. Your sample will be opened in the application. functionality e signature complete word simple anything. Additionally, making use of one service for all of your document management needs, things are quicker, better and cheaper Download the application today!
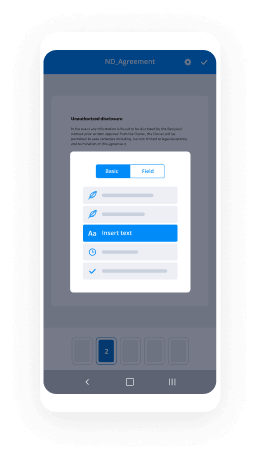

How to sign a PDF file on an Android
What’s the number one rule for handling document workflows in 2020? Avoid paper chaos. Get rid of the printers, scanners and bundlers curriers. All of it! Take a new approach and manage, functionality e signature complete word simple, and organize your records 100% paperless and 100% mobile. You only need three things; a phone/tablet, internet connection and the airSlate SignNow app for Android. Using the app, create, functionality e signature complete word simple and execute documents right from your smartphone or tablet.
How to sign a PDF on an Android
- In the Google Play Market, search for and install the airSlate SignNow application.
- Open the program and log into your account or make one if you don’t have one already.
- Upload a document from the cloud or your device.
- Click on the opened document and start working on it. Edit it, add fillable fields and signature fields.
- Once you’ve finished, click Done and send the document to the other parties involved or download it to the cloud or your device.
airSlate SignNow allows you to sign documents and manage tasks like functionality e signature complete word simple with ease. In addition, the security of your information is priority. Encryption and private servers can be used as implementing the latest features in information compliance measures. Get the airSlate SignNow mobile experience and operate better.






FAQs
-
What will the e-signing landscape look like in 3-5 years time?
Most importantly, we will grow from where we are today (about 1% of all contracts signed on the web) to 50%+ (the majority) in 4-6 years. The broader market will grow 50x, and with that, the market will fundamentally change.At a product/technical level, there will be at least 3 important evolutions as the % of contracts signed on the web that we see at EchoSign:Seamless web workflow (integrations). Today, it's still relatively nichey to, for example, create a document in Google Docs or pull a form from DropBox or Box.net, review/edit/collaborate on the document, send it out to get signed, and then have it all stored on the web, in the cloud. In 3-5 years, the entire contracting workflow and process will be 100% web and cloud based.100% web-based contract. Today, only a minority of e-signed contracts are created purely on the web. Instead, most contracts are still local content - a local PDF, or a local Word document. In 3-5 years, the contract will be 100% web-based and completely abstracted from not only paper, but from an off-line contract creation process. This makes e-signatures a requisite, not optional, part of the contracting process.Dramatically more functionality. From a functionality perspective, the solutions and market are still at a nascent stage. As the market grows 50x in the next few years, the demands for functionality will grow 50x. Whether it's basic things like HTML5 support for e-signing on the iPad, or tailoring the electronic signature experience in real-time based on the country the signer is in, or bigger changes, like true web-based contract collaboration, the bar will continue to go up.Because of this, the market is likely to end up with "2.5" leading players. E-signatures and e-contracting are too nuanced, and require too much workflow and too high a level of user-specific functionality, to become just a feature of another solution. The level of solution complexity certainly is not as high as standalone CRM, for example (where competing with Salesforce.com at this point is impractical), but it is much higher than simple web apps (e.g., document or content storage) or even web conferencing/collaboration (WebEx/GoToMeeting/etc.). The solutions also benefit from scale and users, but do not have a true network effect. Also, electronic signatures have a signNow legal component, which creates challenges to immature products.Thus, 4-5 years out (perhaps not 3), we are likely to see (x) e-signatures having become the primary way contracts are signed, period, with (y) a few leaders (a la WebEx and GoToMeeting) whose products are deeply integrated with, but not subsumed by, the workflows and integrations of the web, along with a few smaller players with niche offerings and relatively small customer bases.
-
How did an attempt to punish a child backfire?
My stepdad hated letting me do anything that brought me joy. I had a best friend, who was also my only friend because I was being bullied at my new school, and since she lived on the other end of the city and we couldn't hang out much, we would often chat online or talk on the phone. Whenever he came home and I was on the phone, he'd rip the cord out of the wall mid-call because he had “business calls to make". Instead of, you know, telling me in a civil manner that he needed the phone and I should finish up my call. This backfired in so far that I bought myself a cell phone with the money ...
-
What are some great online tools for startups? Why?
Startups need something that can give then maximum at minimum invest because the number of risks is always high! We understand all your needs and hence we have got this product for you- PayUnow!Be it any startup: food, automobiles, e-commerce, travel, IT, education or homemakers, this one is for you! It is available for FREE for Android and iOS users. Let customers discover you as you upload pictures of delicacies. To collect online payments easily, anytime and anywhere, all you have to do is share a unique business link or website which you will create with us for FREE! Here’s why you should download the app NOW:It is FREEAllows you to create a business website with zero maintenance costHas the lowest TDR in the market i.e 1.99+GST!Lets you showcase your productsAllow you to add contact details and locationMultiple payment options supportedYour customers do not need an app! All you need to accept payments directly in your bank is one link: you can choose this link for FREE!Quick and paperless bank verification and documentationPayUnow is a product of India’s largest Fintech Company- PayU! Join the communtiy of 4.5 lakhs+ businesses like you! We look forward to empowering the SMBs and give them a relief from the hassles of payments so that the only thing you need to focus is your business growth! We are continuously creating a guide to assist you with the best. Learn how to sign up, edit, share and verify by visiting here:
-
What are probabilistic graphical models, and why are they useful?
These are Probabilistic Graphical Models. They are arguably our most complete and promising toolkit for inferring truth from complexity. They're born from a single set of principles that endow our machines to dominate chess, diagnose disease, translate language, decipher sound, recognize images and drive cars. 'Neural Networks' and 'Probabilistic Programming' are famous signatures of the Machine Learning community simply because they are effective tool sets for applying these devices.My aim here is to reveal the machinery behind this magic. I intend to show what they are, why we use them and how we actually use them. To do that, I’ve answered seven questions on this subject:What are Probabilistic Graphical Models and why are they useful?What is 'exact inference' in the context of Probabilistic Graphical Models?What is Variance Inference in the context of Probabilistic Graphical Models?How are Monte Carlo methods used to perform inference in Probabilistic Graphical Models?How are the parameters of a Bayesian Network learned?How are the parameters of a Markov Network learned?How is the graph structure of Probabilistic Graphical Models learned?I realize this is a ton to digest, especially for internet browsing, but allow me to sell you. This information is typically delivered with a worthwhile 1000+ page textbook to graduate computer scientists. We can 80/20 these ideas with just a few answers! It'll take discipline, but you'll gain a surprisingly good understanding of an absolutely foundational theory of Machine Learning.As a compromise, I've structured things such that you need only read a subset of these answers to get a full picture. Here's a map of that structure:For example, if you read [math]1 \rightarrow 2 \rightarrow 6 \rightarrow 7[/math], you'll get a complete taste. Also, I'll include refreshers at the beginning of each answer - this should make things more self contained. (If you read these answers in sequence, I'd skip those refreshers, as they will sound redundant.)If this sounds like a good deal to you, please follow those questions!Now, let's start walking.Notation GuideAs a first stop, we'll review notation, an admittedly boring place. But, it's my unconventional belief that most confusion is due to notation. So if we wish to survive, we'll need a few tips:An upper case non-bold letter indicates a single random variable ('RV'). The same letter lower cased with a super script indicates a specific value that RV may take. For example, [math]X=x^1[/math] is the event the RV [math]X[/math] took on the value [math]x^1[/math]. We call this event an assignment. The set of unique values an RV may take is [math]Val(X)[/math]. So we might have [math]Val(X)=\{x^0,x^1\}[/math] in this case.A bold upper case letter indicates a set of RVs (like [math]\mathbf{X}[/math]) and a bold lower case letter indicates a set of values they may take. For example, we may have [math]\mathbf{X}=\{A,B\}[/math] and [math]\mathbf{x}=\{a^3,b^1\}[/math]. Then the event [math]\mathbf{X}=\mathbf{x}[/math] is the event that [math]A=a^3[/math] happens and [math]B=b^1[/math] happens. Naturally, [math]Val(\mathbf{X})[/math] is the set of all possible unique joint assignments to the RVs in [math]\mathbf{X}[/math].If you see [math]\mathbf{x}[/math] (or [math]\mathbf{y}[/math] or [math]\mathbf{z}[/math] etc...) within a probability expression, like [math]P(\mathbf{x}|\cdots)[/math] or [math]P(\cdots|\mathbf{x})[/math], that's always an abbreviation of the event '[math]\mathbf{X}=\mathbf{x}[/math]'.Perhaps confusingly, we also abbreviate the event '[math]\mathbf{X}=\mathbf{x}[/math]' as '[math]\mathbf{X}[/math]', though this isn't a clean abbreviation. Omission of [math]\mathbf{x}[/math] means one of two things: either we mean this for any given [math]\mathbf{x}[/math] or for all possible [math]\mathbf{x}[/math]'s. As an example for the latter case, 'calculate [math]P(\mathbf{X})[/math]' would mean calculate the set of probabilities [math]P(\mathbf{X}=\mathbf{x})[/math] for all [math]\mathbf{x}\in Val(\mathbf{X})[/math].[math]\sum_\mathbf{X}f(\mathbf{X})[/math] is shorthand for [math]\sum_{\mathbf{x}\in Val(\mathbf{X})}f(\mathbf{X}=\mathbf{x})[/math]. This is similarly true for [math]\prod_\mathbf{X}(\cdot)[/math] and [math]\textrm{argmin}_\mathbf{X}(\cdot)[/math]. Look out for this one - it can sneak in there and change things considerably.You may see equations like [math]f(A,B,C)=g(\mathbf{X})h(\mathbf{Y})[/math]. They look strange - the RVs on the left aren't on the right! Well, in such cases, you also have something like [math]\mathbf{X} = \{A,B\}[/math] and [math]\mathbf{Y} = \{B,C\}[/math]. So the equation really is [math]f(A,B,C)=g(A,B)h(B,C)[/math].Probability distributions are references with a [math]P[/math], [math]\textrm{Q}[/math], [math]q[/math] or [math]\pi[/math]. Keep in mind that distributions are a special kind of function. Remember that!Everything is in reference to the discrete case. Unfortunately, the continuous case is not a simple generalization from the discrete case. The minor exception is in the visuals. The discrete case is less friendly to graphs, so I might use some continuous distributions. As it relates to the discussion, pretend these are in fact discrete distributions with a fine granularity.Almost all of this notation comes from the text Probabilistic Graphical Models - one of those 1000 page monsters. That book is extremely thorough, and should be considered stop number 8.Still here? You must have discipline! Onto the fun stuff - we ask:What generic problem do PGMs address?Our goal is to understand a complex system. We assume the complex system manifests as [math]n[/math] RVs, which we may write as [math]\mathcal{X} = \{X_1,X_2,\cdots,X_n\}[/math] [1][2]. We take it that 'a good understanding' means we can answer two types of questions accurately and efficiently for these RVs. If we say [math]\mathbf{Y}[/math] and [math]\mathbf{E}[/math] are two given subsets of [math]\mathcal{X}[/math], then those questions are:Probability Queries: Compute the probabilities [math]P(\mathbf{Y}|\mathbf{E}=\mathbf{e})[/math]. That is, what is the distribution of the RV's of [math]\mathbf{Y}[/math] given we have some observation of the RVs of [math]\mathbf{E}[/math]?MAP Queries: Determine [math]\textrm{argmax}_\mathbf{Y}P(\mathbf{Y}|\mathbf{E}=\mathbf{e})[/math]. That is, determine the most likely assignments of RVs given an assignment of other RVs.Before continuing, we should point a few things out:Since [math]\mathbf{Y}[/math] and [math]\mathbf{E}[/math] are any two subsets of [math]\mathcal{X}[/math], there is potentially a remaining set (call it [math]\mathbf{Z}[/math]) that's in [math]\mathcal{X}[/math]. In other words, [math]\mathbf{Z} = \mathcal{X} - \{\mathbf{Y},\mathbf{E}\}[/math]. This set appears left out of our questions, but is very much at play. We have to sum these RVs out, which can considerably complicate our calculations. For example, [math]P(\mathbf{y}|\mathbf{e})[/math] is actually [math]\sum_\mathbf{Z}P(\mathbf{y},\mathbf{Z}|\mathbf{e})[/math].We haven't mentioned any model yet. This set up is asking generically for probabilities and values that accurately track reality.To this end, we are assisted by the fact that we have some, at least partial, joint observations of [math]\mathcal{X}[/math]. However, some of our [math]n[/math] RVs may never be observed. These are called 'hidden' variables and they will complicate our lives later on.This set up is extremely general, and as such, this problem is extremely hard.The problem with joint distributions.Our starting point, perhaps surprisingly, will be to consider the joint distribution of our RVs [math]\mathcal{X}[/math], which we aren't given in real application (but we'll get there). We'll call that joint distribution [math]P[/math]. Conceptually, we can think of this as a table that lists out all possible joint assignments of [math]\mathcal{X}[/math] and their associated probabilities. So if [math]\mathcal{X}[/math] is made up of 10 RVs, each of which can take 1 of 100 values, this table has [math]100^{10}[/math] rows, each indicating a particular assignment of [math]\mathcal{X}[/math] and it's probability.The issue is, for a complex system, this table is too big. Even if we had the crystal ball luxury of having [math]P[/math], we can't handle it. So now what?The Conditional Independence statementWe need a compact representation of [math]P[/math] - something that gives us all the information of that table, but doesn’t involve writing it down. To this end, our saving grace is the Conditional Independence (CI) statement:Given subsets of RVs [math]\mathbf{X}[/math], [math]\mathbf{Y}[/math] and [math]\mathbf{Z}[/math] from [math]\mathcal{X}[/math], we say [math]\mathbf{X}[/math] is conditionally independent of [math]\mathbf{Y}[/math] given [math]\mathbf{Z}[/math] if[math]P(\mathbf{x},\mathbf{y}|\mathbf{z})=P(\mathbf{x}|\mathbf{z})P(\mathbf{y}|\mathbf{z})\tag*{}[/math]for all [math]\mathbf{x}\in Val(\mathbf{X})[/math], [math]\mathbf{y}\in Val(\mathbf{Y})[/math] and [math]\mathbf{z}\in Val(\mathbf{Z})[/math]. This is stated as '[math]P[/math] satisfies [math](\mathbf{X}\perp \mathbf{Y}|\mathbf{Z})[/math][3]'Now, if we had sufficient calculation abilities, we could calculate the left side and the right side for a distribution [math]P[/math]. If the equations hold for all values, then, by definition, the CI statement holds. Intuitively, though not obviously, this means that if you are given the assignment of [math]\mathbf{Z}[/math], then knowing the assignment of [math]\mathbf{X}[/math] will never help you guess [math]\mathbf{Y}[/math] (and vice versa). In other words, [math]\mathbf{X}[/math] provides no information for predicting [math]\mathbf{Y}[/math] beyond what [math]\mathbf{Z}[/math] has. Similarly, you can't predict [math]\mathbf{X}[/math] from [math]\mathbf{Y}[/math] any better.Knowing such statements turns out to be massively useful - they give us that compact representation we need. To see this, let's say [math](X_i \perp X_j)[/math] for all [math]i \in \{1,\cdots,10\}[/math] and [math]j \in \{1,\cdots,10\}[/math] where [math]i\neq j[/math]. This is to say, all RVs are independent of all other RVs. It turns out that with these statements, we only need to know the marginal probabilities of each value for each RV (which is a total of [math]10\cdot 100=1000[/math] values) and may reproduce all the probabilities of [math]P[/math]. So if we are considering the case where [math]\mathbf{X}=\mathcal{X}[/math] and would like to know the probability [math]P(\mathbf{X}=\mathbf{x})[/math], we simply return [math]\prod_{i=1}^{10}P(X_i=x_i)[/math], where [math]x_i[/math] is the [math]i[/math]-th element of [math]\mathbf{x}[/math].Though this isn't just a save on storage. This is a simplification on [math]P[/math] that will ease virtually any interaction with [math]P[/math], including summing over many assignments and finding the most likely assignment. So at this point, I'd like you to think that CI statements regarding [math]P[/math] are a requirement for wielding it.Now put a pin in this and let's switch gears.The Bayesian NetworkIt's time to introduce the first type of PGM - the Bayesian Network ('BN'). A BN refers to two things, both in relation to some [math]\mathcal{X}[/math]: a BN graph (called [math]\mathcal{G}[/math]) and an associated probability distribution [math]P_B[/math]. [math]\mathcal{G}[/math] is a set of nodes, one for each RV of [math]\mathcal{X}[/math], and a set of directed edges, such that there are no directed cycles. Said differently, it's a DAG. [math]P_B[/math] is a distribution with probabilities for assignments of [math]\mathcal{X}[/math] using a certain rule and Conditional Probability Tables ('CPTs' and 'CPDs'), which augment [math]\mathcal{G}[/math]. That rule, called the 'Chain Rule for BNs', for determining probabilities can be written:[math]P_B(X_1,\cdots,X_n)=\prod_{i=1}^n P_B(X_i|\textrm{Pa}_{X_i}^\mathcal{G})\tag*{}[/math]where [math]\textrm{Pa}_{X_i}^\mathcal{G}[/math] indicates the set of parent nodes/RVs of [math]X_i[/math] according to [math]\mathcal{G}[/math]. The CPDs tell us what the [math]P_B(X_i|\textrm{Pa}_{X_i}^\mathcal{G})[/math] probabilities are. That is, a CPD lists out the probabilities of all assignments of [math]X_i[/math] given any joint assignment of [math]\textrm{Pa}_{X_i}^\mathcal{G}[/math][4]. These CPDs are the parameters of our model. Their form is to list out actual conditional probabilities from [math]P_B[/math].To help, let's consider a well utilized example from that monstrous text: the 'Student Bayesian Network'. Here, we're concerned with a system of five RVs: a student's intelligence ([math]I[/math]), their class's difficulty ([math]D[/math]), their grade in that class ([math]G[/math]), their letter of recommendation ([math]L[/math]) and their SAT score ([math]S[/math]). So [math]\mathcal{X}=\{I,D,G,L,S\}[/math]. The BN graph along with the CPDs can be represented as:According to our rule, we have that any joint assignment of [math]\mathcal{X}[/math] factors as:So we would calculate a given assignment as:Not too bad, right? All this is to show is that a BN along with CPDs gives us a way to calculate probabilities for assignments of [math]\mathcal{X}[/math].Now we're ready for:The big idea.It's so big, it gets its own quote block:The BN graph, just those nodes and edges, implies a set of CI statements regarding it's accompanying [math]P_B[/math].It's a consequence of the Chain Rule for calculating probabilities. As a not-at-all-obvious result, a BN graph represents all [math]P[/math]'s that satisfy these CI statements and each of those [math]P[/math]'s could be attained with an appropriate choice of CPDs.For a BN, one form of those CI statements are:[math](X_i \perp\textrm{NonDescendants}_{X_i}|\textrm{Pa}_{X_i}^\mathcal{G})[/math] for [math]X_i \in \mathcal{X}[/math]So in the student example, we'd have this set:The third statement tells us that if you already know the student's intelligence and their class's difficulty, then knowing their SAT score won't help you guess their grade. This is because the SAT score is correlated with their grade only via their intelligence, and you already know that.These are referred to as the local semantics of the BN graph. To complicate matters, there are almost always many other true CI statements associated with a BN graph outside of the local semantics. To determine those by inspecting the graph, we use a scary 'D-separation' algorithm that I will shamelessly not explain.There is a reason this is so important. Since a BN graph is a way of representing CI statements and such statements are a requirement for handling a complex system's joint distribution (if you had it), then this is a good reason to use a BN to represent such systems. If we can accurately represent a system with a BN, we will be able to calculate our probability and MAP queries. Therefore, BNs will solve our problems when we're dealing with a certain class of [math]P[/math]'s. This choice, unsurprisingly, is called our representation.But there's an issue - I said a 'class' of [math]P[/math]'s. It's not hard to invent [math]P[/math]'s that come with CI statements a BN cannot represent.So now what? Well, we have other tools, the biggest of which is...The Markov NetworkA Markov Network ('MN') is likewise composed of a graph ([math]\mathcal{H}[/math]) and a probability distribution ([math]P_M[/math]). Though this time, the graph's edges are undirected and it may have cycles. The consequence is that a MN can represent a different set of CI statements. But, the lack of directionality means we can no longer use CPDs. Instead, that information is delivered with a factor, which is a function (function! remember it) that maps from an assignment of some subset of [math]\mathcal{X}[/math] to some nonnegative number. These factors are used to calculate probabilities with the 'Gibbs Rule'[5].To understand the Gibbs Rule, we must define a complete subgraph. A ‘subgraph’ is exactly what it sounds like - we make a subgraph by picking a set of nodes from [math]\mathcal{H}[/math] and including all edges from [math]\mathcal{H}[/math] that are between nodes from this set. A 'complete' graph is one which has every edge it can - each node has an edge to every other node.Now, let's say [math]\mathcal{H}[/math] breaks up into a set of [math]m[/math] complete subgraphs. By 'break up', I mean that the union of all nodes and edges across these subgraphs gives us all the nodes and edges from [math]\mathcal{H}[/math]. Let's write the RVs associated with the nodes of these subgraphs as [math]\{\mathbf{D}_i\}_{i=1}^m[/math]. Let's also say we have one factor (call it [math]\phi_i(\cdot)[/math]) for each of these. We refer to these factors together with [math]\Phi[/math], so [math]\Phi=\{\phi_i(\cdot)\}_{i=1}^m[/math]. For terminology's sake, we say that the 'scope' of the factor [math]\phi_i(\cdot)[/math] is [math]\mathbf{D}_i[/math] because [math]\phi_i(\cdot)[/math] takes an assignment of [math]\mathbf{D}_i[/math] as input.Finally, the Gibbs Rule says we calculate a probability as:where(It's hidden from this notation, but we're assuming it's clear how to match up the assignment of [math]X_1,\cdots,X_n[/math] with the assignments of the [math]\mathbf{D}_i[/math]'s.)Wait - the MN was introduced because it represents a different set of CI statement. So, which ones? It's considerably simpler in the case of a MN. A MN implies the CI statement [math](\mathbf{X} \perp \mathbf{Y}|\mathbf{Z})[/math] if all paths between [math]\mathbf{X}[/math] and [math]\mathbf{Y}[/math] go through [math]\mathbf{Z}[/math]. Easy!Now let's get specific. Below is an MN for the system [math]\mathcal{X}=\{A,B,C,D\}[/math] and the CI statements it represents:As you may notice, it's not hard to write those CI statements by viewing the graph.While we're here, let's write out the Gibbs Rule. By looking at this, we could identify our complete subgraphs as: [math]\{\{A,B\},\{B,C\},\{C,D\},\{D,A\}\}[/math]. With that, we calculate a probability as:whereTo repeat, each [math]\phi_i(\cdot,\cdot)[/math] is just a function that maps from it's given joint assignment to some nonnegative. So if [math]A[/math] and [math]B[/math] could only take on two values each, [math]\phi_1(\cdot,\cdot)[/math] would relate the four possible assignments to four nonnegative numbers. These functions serve as our parameters just as the CPDs did. Determining these functions brings us from a class of [math]P[/math]'s to a specific [math]P[/math] within it, defined with probabilities.But, ahem, uhh… there's an issue. In the BN case, I said:As a not-at-all-obvious result, a BN graph represents all [math]P[/math]'s that satisfy its CI statements and each of those [math]P[/math]'s could be attained with an appropriate choice of CPDs.The analogous is not true in the case of MNs. There may exist a [math]P[/math] that satisfies the CI statements of a MN graph, but we can't calculate it's probabilities with the Gibbs rule. Damn!Fortunately, these squirrely [math]P[/math]'s falls into a simple, though large, category: those which assign a zero probability to at least one assignment. This leads us to the Hammersley-Clifford theorem:If [math]P[/math] is a positive distribution ([math]P(\mathbf{X}=\mathbf{x})>0[/math] for all [math]\mathbf{x} \in Val(\mathcal{X})[/math]) which satisfies the CI statements of [math]\mathcal{H}[/math], then we may use the Gibbs Rule, along with a choice of complete subgraphs and associated factors, to yield the probabilities of [math]P[/math]. [6]And that about does it for the basics of MNs. They are just another way of representing another class of [math]P[/math]'s.How do BNs and MNs compare?At this point, we're not evolved enough for a full comparison, so let's do a partial one.First, it's clearly easier to determine CI statements in a MN - no fancy D-separation algorithm required. This follows from their simple symmetric undirected edges, which make them a natural candidate for certain problems. Broadly, MNs do better when we have decidedly associative observations - like pixels on a screen or concurrent sounds. BNs are better suited when we suspect the RVs attests to distinct components of some causal structure. Timestamps and an outside expectation of what's producing the data are helpful for that.Also, there's a certain overlap between a MN and a BN that'll unify our discussion in later answers. That is, the probabilities produced by the Chain Rule of any given BN can be exactly reproduced by the Gibbs Rule of a specially defined MN. To see this, look at the Chain Rule - [math]P_B(X_i|\textrm{Pa}_{X_i}^\mathcal{G})[/math] is just the conditional probability of some (unspecified) [math]X_i[/math] value given some assignment of the parent RVs. Well, to translate this to the Gibbs Rule, let [math]\mathbf{D}_i=\{X_i\}\cup\textrm{Pa}_{X_i}^\mathcal{G}[/math]. Next, define [math]\phi_i(\mathbf{D}_i)[/math] to produce the same output you'd get from looking up the BN conditional probability in the CPD (which is [math]P_B(X_i|\textrm{Pa}_{X_i}^\mathcal{G})[/math]). Awesome - now the Gibbs Rule is the same expression as the Chain Rule. This is useful because we can speak solely in terms of the Gibbs Rule and whatever we discover, we know will also work for the Chain Rule (and hence BNs). What this doesn't mean is that MNs are a substitute for BNs. If you were to look at this invented MN, it would likely imply way more edges in its graph and therefore, fewer CI statements and therefore, a wider and more unwieldy class of [math]P[/math]'s. In other words, BNs are still useful representations.But there's more to learn.Let's say we determined our graphical model along with its parameters. How do we actually answer those queries? Well, I have three suggestions:2. What is 'exact inference' in the context of Probabilistic Graphical Models?3. What is Variance Inference in the context of Probabilistic Graphical Models?4. How are Monte Carlo methods used to perform inference in Probabilistic Graphical Models?Footnotes[1] This is the one exception where we don't refer to a set of RVs with a bold uppercase letter.[2] This actually isn't the fully general problem specification. In complete generality, the set of RVs should be allowed to grow/shrink over time. That, however, is outside what I expect to accomplish in these posts.[3] There is a subtlety of language here. Often we'll say '[math]P[/math] satisfies these CI statements'. That means those CI statements are true for [math]P[/math], but others may be true as well. So it means 'these CI statements' are a subset of all [math]P[/math]'s true CI statements. This technicality matters, so keep an eye out for it.[4] If [math]X_i[/math] doesn't have any parents, then the CPD is the unconditional probability distribution of [math]X_i[/math].[5] This isn't a real name I'm aware of, but the form of that distribution makes it a Gibbs distribution and I'd like to maintain an analogy to BNs, which had the Chain Rule.[6] The implication goes the other way as well: If the probabilities of [math]P[/math] can be calculated with the Gibbs Rule, then it's a positive distribution which satisfies CI statements implied by a graph which has complete subgraphs of RVs that correspond to the RVs of each factor. This direction, however, doesn't fit into the story I'm telling, so it sits as a lonely footnote.Sources[1] Koller, Daphne; Friedman, Nir. Probabilistic Graphical Models: Principles and Techniques (Adaptive Computation and Machine Learning series). The MIT Press. Kindle Edition. This is the source of the notation, the graphics in this answers (with permission) and my appreciation for this subject.
Trusted esignature solution— what our customers are saying







Get legally-binding signatures now!
Related searches to Complete eSignature Word Simple
Frequently asked questions
How do i add an electronic signature to a word document?
How to esign a filable pdf file?
How to sign an e-mail?
Get more for Complete eSignature Word Simple
- How Do I Electronic signature New Hampshire Plumbing Document
- Help Me With Electronic signature New Hampshire Plumbing Document
- How Can I Electronic signature New Hampshire Plumbing Document
- Can I Electronic signature New Hampshire Plumbing Word
- Can I Electronic signature New Hampshire Plumbing Document
- How To Electronic signature New Hampshire Plumbing Document
- How To Electronic signature New Hampshire Plumbing Document
- How Do I Electronic signature New Hampshire Plumbing Document
Find out other Complete eSignature Word Simple
- General partnership package texas form
- Texas directive form
- Texas contract deed 497327855 form
- Texas package form
- Revised uniform anatomical gift act donation texas
- Texas employment form
- Anatomical gift 497327859 form
- Texas employment form 497327860
- Newly widowed individuals package texas form
- Employment interview package texas form
- Employment employee personnel file package texas form
- Assignment of mortgage package texas form
- Assignment of lease package texas form
- Texas purchase 497327866 form
- Cancellation release 497327867 form
- Texas premarital agreement 497327868 form
- Painting contractor package texas form
- Framing contractor package texas form
- Foundation contractor package texas form
- Plumbing contractor package texas form