Anneal Signature Block Order with airSlate SignNow
Award-winning eSignature solution




Do more online with a globally-trusted eSignature platform
Outstanding signing experience
Robust reporting and analytics
Mobile eSigning in person and remotely
Industry regulations and compliance
Anneal signature block order, faster than ever
Helpful eSignature extensions
See airSlate SignNow eSignatures in action




airSlate SignNow solutions for better efficiency
Our user reviews speak for themselves









Why choose airSlate SignNow
-
Free 7-day trial. Choose the plan you need and try it risk-free.
-
Honest pricing for full-featured plans. airSlate SignNow offers subscription plans with no overages or hidden fees at renewal.
-
Enterprise-grade security. airSlate SignNow helps you comply with global security standards.

Your step-by-step guide — anneal signature block order
Employing airSlate SignNow’s eSignature any company can speed up signature workflows and eSign in real-time, delivering a better experience to customers and staff members. anneal signature block order in a few easy steps. Our handheld mobile apps make operating on the run possible, even while off the internet! Sign contracts from any place worldwide and complete deals faster.
Follow the step-by-step guideline to anneal signature block order:
- Log on to your airSlate SignNow account.
- Find your record within your folders or upload a new one.
- Open up the template adjust using the Tools list.
- Place fillable areas, add textual content and eSign it.
- Add several signers via emails and set the signing order.
- Indicate which users will receive an completed doc.
- Use Advanced Options to limit access to the record add an expiration date.
- Click Save and Close when finished.
In addition, there are more advanced tools accessible to anneal signature block order. Add users to your shared work enviroment, view teams, and keep track of collaboration. Numerous people across the US and Europe concur that a system that brings everything together in a single holistic digital location, is what companies need to keep workflows working efficiently. The airSlate SignNow REST API allows you to integrate eSignatures into your app, website, CRM or cloud storage. Check out airSlate SignNow and get faster, easier and overall more efficient eSignature workflows!
How it works
airSlate SignNow features that users love






See exceptional results anneal signature block order with airSlate SignNow
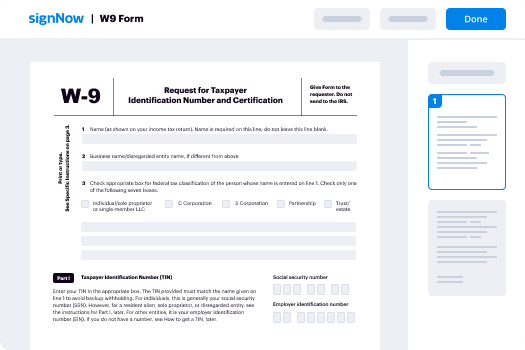
How to complete and sign a document online
Try out the fastest way to anneal signature block order. Avoid paper-based workflows and manage documents right from airSlate SignNow. Complete and share your forms from the office or seamlessly work on-the-go. No installation or additional software required. All features are available online, just go to signnow.com and create your own eSignature flow.
A brief guide on how to anneal signature block order in minutes
- Create an airSlate SignNow account (if you haven’t registered yet) or log in using your Google or Facebook.
- Click Upload and select one of your documents.
- Use the My Signature tool to create your unique signature.
- Turn the document into a dynamic PDF with fillable fields.
- Fill out your new form and click Done.
Once finished, send an invite to sign to multiple recipients. Get an enforceable contract in minutes using any device. Explore more features for making professional PDFs; add fillable fields anneal signature block order and collaborate in teams. The eSignature solution gives a secure workflow and operates based on SOC 2 Type II Certification. Ensure that all of your records are protected so no person can change them.
How to eSign a PDF in Google Chrome
Are you looking for a solution to anneal signature block order directly from Chrome? The airSlate SignNow extension for Google is here to help. Find a document and right from your browser easily open it in the editor. Add fillable fields for text and signature. Sign the PDF and share it safely according to GDPR, SOC 2 Type II Certification and more.
Using this brief how-to guide below, expand your eSignature workflow into Google and anneal signature block order:
- Go to the Chrome web store and find the airSlate SignNow extension.
- Click Add to Chrome.
- Log in to your account or register a new one.
- Upload a document and click Open in airSlate SignNow.
- Modify the document.
- Sign the PDF using the My Signature tool.
- Click Done to save your edits.
- Invite other participants to sign by clicking Invite to Sign and selecting their emails/names.
Create a signature that’s built in to your workflow to anneal signature block order and get PDFs eSigned in minutes. Say goodbye to the piles of papers on your desk and start saving money and time for more important activities. Choosing the airSlate SignNow Google extension is a great practical decision with plenty of advantages.
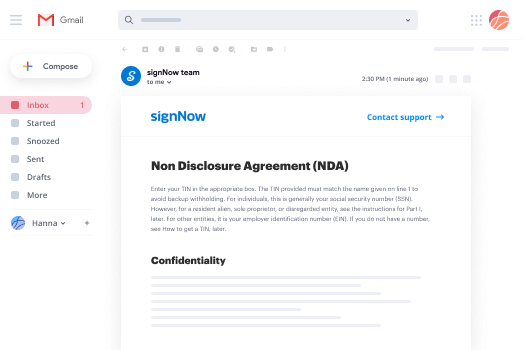
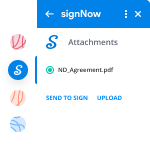

How to sign an attachment in Gmail
If you’re like most, you’re used to downloading the attachments you get, printing them out and then signing them, right? Well, we have good news for you. Signing documents in your inbox just got a lot easier. The airSlate SignNow add-on for Gmail allows you to anneal signature block order without leaving your mailbox. Do everything you need; add fillable fields and send signing requests in clicks.
How to anneal signature block order in Gmail:
- Find airSlate SignNow for Gmail in the G Suite Marketplace and click Install.
- Log in to your airSlate SignNow account or create a new one.
- Open up your email with the PDF you need to sign.
- Click Upload to save the document to your airSlate SignNow account.
- Click Open document to open the editor.
- Sign the PDF using My Signature.
- Send a signing request to the other participants with the Send to Sign button.
- Enter their email and press OK.
As a result, the other participants will receive notifications telling them to sign the document. No need to download the PDF file over and over again, just anneal signature block order in clicks. This add-one is suitable for those who like focusing on more significant goals rather than burning up time for practically nothing. Boost your day-to-day compulsory labour with the award-winning eSignature service.
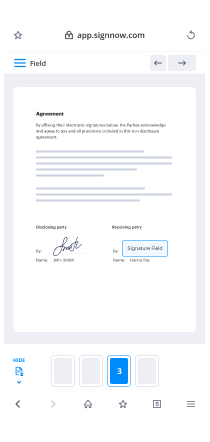


How to sign a PDF file on the go with no app
For many products, getting deals done on the go means installing an app on your phone. We’re happy to say at airSlate SignNow we’ve made singing on the go faster and easier by eliminating the need for a mobile app. To eSign, open your browser (any mobile browser) and get direct access to airSlate SignNow and all its powerful eSignature tools. Edit docs, anneal signature block order and more. No installation or additional software required. Close your deal from anywhere.
Take a look at our step-by-step instructions that teach you how to anneal signature block order.
- Open your browser and go to signnow.com.
- Log in or register a new account.
- Upload or open the document you want to edit.
- Add fillable fields for text, signature and date.
- Draw, type or upload your signature.
- Click Save and Close.
- Click Invite to Sign and enter a recipient’s email if you need others to sign the PDF.
Working on mobile is no different than on a desktop: create a reusable template, anneal signature block order and manage the flow as you would normally. In a couple of clicks, get an enforceable contract that you can download to your device and send to others. Yet, if you want a software, download the airSlate SignNow app. It’s secure, fast and has a great design. Try out smooth eSignature workflows from your workplace, in a taxi or on an airplane.
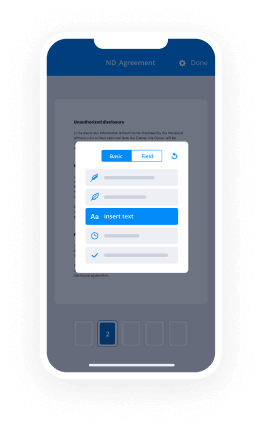

How to sign a PDF employing an iPad
iOS is a very popular operating system packed with native tools. It allows you to sign and edit PDFs using Preview without any additional software. However, as great as Apple’s solution is, it doesn't provide any automation. Enhance your iPhone’s capabilities by taking advantage of the airSlate SignNow app. Utilize your iPhone or iPad to anneal signature block order and more. Introduce eSignature automation to your mobile workflow.
Signing on an iPhone has never been easier:
- Find the airSlate SignNow app in the AppStore and install it.
- Create a new account or log in with your Facebook or Google.
- Click Plus and upload the PDF file you want to sign.
- Tap on the document where you want to insert your signature.
- Explore other features: add fillable fields or anneal signature block order.
- Use the Save button to apply the changes.
- Share your documents via email or a singing link.
Make a professional PDFs right from your airSlate SignNow app. Get the most out of your time and work from anywhere; at home, in the office, on a bus or plane, and even at the beach. Manage an entire record workflow effortlessly: create reusable templates, anneal signature block order and work on PDFs with business partners. Turn your device into a potent enterprise instrument for executing deals.

How to sign a PDF file using an Android
For Android users to manage documents from their phone, they have to install additional software. The Play Market is vast and plump with options, so finding a good application isn’t too hard if you have time to browse through hundreds of apps. To save time and prevent frustration, we suggest airSlate SignNow for Android. Store and edit documents, create signing roles, and even anneal signature block order.
The 9 simple steps to optimizing your mobile workflow:
- Open the app.
- Log in using your Facebook or Google accounts or register if you haven’t authorized already.
- Click on + to add a new document using your camera, internal or cloud storages.
- Tap anywhere on your PDF and insert your eSignature.
- Click OK to confirm and sign.
- Try more editing features; add images, anneal signature block order, create a reusable template, etc.
- Click Save to apply changes once you finish.
- Download the PDF or share it via email.
- Use the Invite to sign function if you want to set & send a signing order to recipients.
Turn the mundane and routine into easy and smooth with the airSlate SignNow app for Android. Sign and send documents for signature from any place you’re connected to the internet. Generate professional-looking PDFs and anneal signature block order with a few clicks. Assembled a flawless eSignature workflow with only your mobile phone and improve your overall productivity.
Get legally-binding signatures now!
What active users are saying — anneal signature block order








Anneal signature block order
hello and welcome to today's acm tech talk this webcast is part of acm's commitment to lifelong learning and professional development serving a global membership of computing professionals and students i'd like to introduce today's moderator hamel hussein he's a staff machine learning engineer at github his focus is on creating developer tools powered by machine learning previously hamel was a data scientist at airbnb where he worked on growth marketing and a data robot where he helped build automated machine learning tools for data scientists he also regularly contributes to open source projects which recently include fast.ai jupiter and uberflow for more on hamel's background you can check out the bio widget on your screen i would also like to introduce today's speaker jeremy howard is a data scientist researcher developer educator and entrepreneur he's a founding researcher at fast.ai a research institute dedicated to making deep learning more accessible he's also a distinguished research scientist at the university of san francisco the chair of wicklow ai at medicine research initiative and is chief scientist at platform.ai previously jeremy was the founding ceo of analytic which was the first company to apply deep learning to medicine and was selected as one of the world's top 50 smartest companies by mit tech review two years running he was the president and chief scientist of the data science platform kaggle where he was the top-ranked participant in international machine learning competitions two-year running he was the founding cf ceo of two successful australian startups fast mail and optimal decision group the latter which was purchased by lexus nexus jeremy has invested and mentored and advised many startups and contributed many open source projects he has written for the guardian usa today and the washington post and is a frequent guest on tv shows and has a highly popular tech talk on ted.com the wonderful and terrifying implications of computers that can learn jeremy is also a co-founder of the global mask for all movement jeremy without further ado take it away thanks so much jan um today i want to talk about um some pretty successful experiments we've been making in the last few years around applying some i guess fairly basic software engineering principles to the development of deep learning software and deep learning research which for software engineers amongst you might sound like a pretty obvious thing to do it's software so you should use good software engineering but um surprisingly um a lot of pretty basic software engineering principles have not been well followed in deep learning software development so far and so i want to show you some successes we've had in in following some of these kinds of principles for those of you that don't know i work at fast.ai which is a self-funded research and development lab and we do a number of things we build software provide education do basic academic research and publish papers and develop community all around the idea of making deep learning more accessible when we started doing this a few years ago deep learning really was pretty much exclusively the domain of a very very small number of highly qualified academics who did not really have a very broad range of backgrounds and i'm happy to say that with our work and the work of other organizations and people deep learning is becoming increasingly more accessible and so when i say accessible that means it should need less educational background less data less compute resources less money and so forth so um at fasted ai i've built a number of things uh a number of software libraries in particular uh generally around the deep learning space a lot of them have been pretty popular most particularly the fastai library which is a layered api for deep learning which a lot of people use it sits on top of the pie torch foundation and um uh we'll be talking a lot about that today um uh fast ai the library and this book deep learning for coders with faster and pi torch were both written by me along with uh silver gujarat and our book deep learning for coders has been super popular and a lot of people um that you might have heard of like peter norvig and eric topple say it's really good as well um the the entire entire book is available for free um or you can purchase a paper copy um and uh all of the software is available for free as well um i mentioned education uh our um course is very popular and as you can see people really like it and the course covers um kind of end to end how to get started with deep learning all the way up to becoming a world-class researcher and reading papers and developing new algorithms and implementing them software and so forth so one of the really interesting things about fast.ai is it's well nowadays it's really um just me in terms of people actually working full-time on this uh for much of the last couple of years it was also with sylvan gusher um and so one of the things people often ask me is how to you know one slash two people do so much um and you know not just doing a lot of work but high quality work that people like and one of my secret weapons is um a critical thing for software engineering something called nbdev nb dev is a software development platform that sits on top of jupiter notebooks um jupiter notebooks was first and foremost really developed as a interactive scientific computing platform but it turns out that um with an interactive platform like jupiter um oh i've got a car alarm that's a bit unfortunate that's not so loud you can't hear me i think i see somebody coming to turn it off yeah all right bad timing um where was i so um uh the thing about jupiter as an interactive environment it's a really a great environment for literate programming and exploratory programming which have many decades of research and development from people like donald knuth brett victor ivan sutherland and literate and exploratory programming are approaches where we treat the practice of programming as a discussion with a human being not just with a computer and where we incorporate video and pictures and prose and we also are working with live code objects rather than just working in a text editor jupiter gives us all that and what mbdev puts on top of it is the ability to take that exploratory programming process and turn it into a publishable python module searchable documentation projects that you could install from pippenconda testing continuous integration and so forth chris lattner has been one of the driving forces behind ex literate programming and exploratory programming uh through his work on swift playgrounds this is the guy who invented swift and llvm amongst other things as described nbdev as a huge step forward in programming environments which was a really exciting thing for me to hear um because for me chris has been somebody i've really admired in this space so what does it look like well fast ai um the library was built with nbdev and if you look at the fast ai documentation you will see that the description of a method includes its signature a link to the source code details and links about where it might have come from the paper that's used that it implements sample code sample outputs from that code that can be any kind of media and this documentation one of the really cool things is that it was actually this entire all the documentation was written with jupiter notebooks which means we can pop a link at the top of every page this is automatically done by nbdev which lets a user open up the documentation itself in collab and colab is a free environment where you can run jupyter notebooks in the cloud on gpus and so here is the exact same thing now running inside colab and this is really great because it means that no longer is documentation just a static thing that you read but it's an interactive thing that you experiment with and that's also good for us because when we're writing documentation we're always thinking about how can we provide the most rich and useful experimental interface for learning about this this code or this api or this feature we're not just thinking like oh let's just throw some text out there and hope it makes sense so then also those notebooks the same notebooks are not just documentation but the actual library itself is written in those same notebooks and the tests are also written in those same notebooks so everything is in one place and the nice thing about that is that when somebody comes along and says oh i'm gonna maybe do a pr to add a feature or add a missing test all the information for the you know the implementation so here's the actual implementation you can see of the of the code and the examples and tests and the descriptions and details are all there in one place so it really helps people to spin up on a project very quickly or if i go back to something i was doing a year ago i couldn't quickly remind myself of what i was doing and why and then a single nbdev command runs all the tests in all the notebooks and tells you how it went and furthermore that is automatically added to continuous integrations or every time you push to any project that was built from nbdev or your tests are run and you're notified of any failures so all this stuff happens from a single settings file which has all the information needed to build your documentation to build your library um to run your tests um to install your project including things like dependencies um and you know this is really important because one of the basic software engineering principles is don't repeat yourself diy and so often we see configuration information repeated in multiple places or at least split over multiple places so one of the basic software engineering principles we try to really stick to is there should be just one place to set up your project um not split over multiple places and certainly not replicate it over multiple places so with nbdev it all sits in one file called settings.any and everything gets read from there regardless of what it's for now exploratory programming environments like jupiter are great for i find most things most of the time and here's some examples of actual source code from nbdev and as you can see the nbdev source code itself is written in nbdev as notebooks and then there's a synchronization process that automatically turns that into what you see on the right which is the actual module um sometimes though it's actually easier to do some things in a text editor like some you know like a quick search and replace or if you're jumping around between tags and stuff like that so one really nice thing is that every part of the module knows as you can see from the comments which part of the notebook it came from so you can also sync back changes in the editor back into the notebook so you can work in wherever your wherever you find it most convenient so you know most of the software engineering practices that most people use nowadays are focused around the text editor environment i would like to see much more move towards a live exploratory coding environment like jupiter but i think each of those tools is good for different things and so it's really important to be able to synchronize back and forth between the two which we can one nice thing about nbdev is that we try to ensure that documentation makes really good use of hyperlinks this is kind of another example of don't repeat yourself rather than explaining in documentation what everything is every time you see it you should just be able to hyperlink to it but you shouldn't have to create a hyperlink manually for code because code can figure out where it is documented so here is what documentation looks like in markdown as we write it in the notebook we just put code symbol names in backticks and then nbdev automatically figures out what those refer to and as you can see it then automatically creates hyperlinks to them and they can figure out which things are actually parameter names and don't actually have hyperlink documentation for instance and it can even hyperlink to as it has here um uh documentation from different libraries so nb dev is actually an ecosystem and any nb dev project registers its own symbol documentation with the central nb dev registry and then all other mb dev projects will automatically create links to each other's documentation and all you have to do is put things in backticks so the documentation that's then generated has all of the stuff you might hope to see it's got an index of pages which can be hierarchical table of contents the opening collab that we mentioned badges so on and so forth so it ends up with a really nice experience for your users um another cool thing is that again kind of the don't repeat yourself software engineering principle is um the information that you put into your documentation page actually comes from a notebook called index index.iponv and the index notebook here's an example of the top of the index notebook from jupiter for fastai that actually automatically becomes your readme file so it's automatically turned down into a markdown readme file it's also automatically turned into your documentation homepage and it's also automatically turned into the description for your pie pie and condor installers so again we kind of try to make sure that you just put your information in one place in this case it's like this is what my library is and how you install it and what the basic features are and you put it in your index notebook and then it appears everywhere else that people might want to see it automatically so one of the things i like about this is that um starting an nbd project takes about 30 seconds you just type nb dev new and you type the name of the project and away you go and that means that i use nbdev even for really small things so for example recently i wanted to create something which would um automatically send a tweet every time there was a new release of any fast.ai um project on github so i created a little thing i called fastwebhook that would have run a little python web server and would listen for uh get web hook calls and when receiving them it would send a tweet so normally that's the kind of thing we might do as a little script just for ourselves but um because everything's just easier to do in nbdev in the first place i wrote it in nbdev which means that i can as you can see i can actually document as i go how does python's http server itself actually work here's actually a test showing you an example of an unbuffered server and so you can see here again the kind of the implementations and the tests and the documentation all mixed up together for this pretty simple little thing that i just spent a couple of hours building and that means that i could actually release that um to uh pie pie and condo so now anybody else can download from pipe or condor um this library even though it's just a quick little thing i built for myself anybody else now can use it if they want to and so this is this is nice right because it means that now your projects don't just have to be little things that you keep for yourself they're automatically they're going to have documentation pip installers conda installers a readme file continuous integration it's all just done for free so part of for us helping data scientists and in particular the deep learning community use better software engineering practices was to provide this tool that would kind of give you the basic software engineering tooling that professional programmers are kind of used to having in their day-to-day jobs in their where they work but now you can have it as part of all of your normal projects as well and you know your your kind of hobby projects or your scientific experiment projects or whatever so this means that data scientists or other domain experts who aren't necessarily day-to-day full-time programmers um can kind of without spending too much time thinking about it get all of the software uh development best practices well not all of them but quite a few of them up and running without really having to think about it so that's the first piece of kind of bringing software engineering to deep learning is to help data scientists get started with the actual development practices um the second is the design of fast ai the library itself which i'll tell you a bit about but first of all i'll give you some examples of some of the kind of research which is embedded into fastai and some of the kind of benefits that we have from that research um so one of the things that we did at fast.ai was we entered a competition to try to train imagenet and sci-fi 10 which are maybe the two most popular um computer vision data sets and there's a competition to see who could train them the fastest to a pretty high accuracy and um much a surprise of a lot of people and i was a bit surprised myself we won some of the main parts of that competition beating companies like google and intel and getting a lot of notice before we started actually it took you know well over 12 hours to train imagenet um google early on in the competition got it to about down to about six hours at first we actually got it down to 18 minutes using standard off-the-shelf hardware that anybody has access to to rent for a few dollars um and that was really a case of um showing people how to do simple things um that that people maybe hadn't thought about much before um another example of some of our research successes has been um we helped kick off what's been kind of called the imagenet moment in nlp which is the development of fine-tuned language models our algorithm called ulm fit fairly directly led to the development at openai of gpt and kind of kicked off a whole series of research breakthroughs around the idea that language models can make a big difference to understanding real human or at least responding appropriately to real human language and again this was really a case of trying to show the research community about how some fairly simple inexpensive easy to understand approaches can make a really big difference so some of the kinds of things that we've done along the way was to say gosh you know normally when training models there's so many hyper parameters you have to tune and the traditional approach to that has been um to spend lots and lots of money uh searching across a whole wide range of different parameters and you end up you know there's a lot of products available from companies like microsoft and google where you can buy a huge amount of compute thousands of dollars and run lots of experiments um instead we just as humans ran some experiments to see if we could figure out whether there's some hyper parameters that just seem to work pretty well or some simple pretty simple ways to set them and one of the things we did was along with a number of fellows was to try out lots of different data sets across lots of different hyper parameters and we actually found a set of hyper parameters uh in this column here where um they were basically the best or close to the best for every data set that we looked at and so these are the kinds of things that we then put into fast ai as defaults so that we try to make it so that when you run when you train a model in fast ai you're going to get a close to state-of-the-art result without having to think too much about it um a lot of the time similar thing with optimizers there's actually been a lot of really interesting development in the world of optimizers over the last year or so optimizers of the things which try to figure out like how do i make a slightly better set of parameters and then repeat that millions and millions of times um in order to train a neural network and we found uh you know some particular approaches to optimization which again basically work pretty much all the time and we make those a default so again people don't really have to think about it to get close to world-class or you know close to best of class results one of the things that really helps though to train models when they're not training well initially is to look inside them and generally they have hundreds of millions of weights or parameters and so you can't look at all of them so along with some of our students we developed this really nice way of drawing pictures of each layer in this case the x-axis is time or matches and the y-axis is a histogram at each column of the activations for that batch for that layer and what it shows here is that the activations uh getting higher and higher and higher and then collapsing and then going higher and collapsing and going higher and collapsing higher and collapsing and this picture which we call the colorful dimension um developed with one of our students stefan we've discovered is a really great snapshot where once you've looked at a few you quickly get a sense from this one picture of how my model is training and if it's not training well why isn't it trading well and this particular picture where particularly at the later layers you get increasing activations and then collapsing activations is a sure sign of a network that's not going to end up training very well and so using this picture we were able to develop a new activation function we called generalized value that as soon as we turned it on basically totally removed that that problem and uh we found it as a result in stable training and we would get much better accuracies um a lot of the time so people really notice when these kinds of best practices that come out of research are embedded in the software they use so for example this person here said that they just recently started experimenting with fast ai and they found that again and again it outperformed my tensorflow 2.0 models despite using the same architectures optimizers and loss functions um and the question on the forum was like how is this possible and then somebody else replied and said yeah that's what we found we spent months tweaking tensorflow and then we switched to fast ai and immediately we got better results so the basic kind of software engineering principle here is really about good defaults and ensuring that the the things where the you the computer needs to be told to do something you you only ask a human the minimum amount if the if the computer can figure it out for itself then have it figure it out for itself um so that's what we do at least you know the kind of the default configuration is we try to make sure everything you just tell that the api is just enough to say like these are the things that can't be figured out automatically and then everything else you know you can change it but they're either configured automatically based on what you've said or there are sensible um well studied defaults for them um so how do we do all that um well the trick is uh to use a very carefully layered api so again this is a pretty standard software engineering principle of layered apis and careful decoupling but it hadn't been much used in deep learning libraries before and there was a little bit but once you kind of started digging under the covers of the top level user facing api you would quickly find this kind of real mess of of one-off functions so with fast ai we've made sure that each layer of the api is is fully documented and is designed to be something that you can hack at and change and then everything else will work together with your changes [Music] so starting by looking at the top layer what do actually users work with most users are going to work with the applications layer where there are four applications um and everything i'm describing here is actually much more fully documented in our peer-reviewed paper and information um so go check that out if you'd like to learn more about any of this um so the four uh applications the first one is fastai.vision which does a wide range of computer vision um deep learning modeling activities um for example here's a complete uh end-to-end uh file that will train an image classifier to recognize 37 different dog and cat breeds now the key thing to note isn't at this stage the details of the api but the fact that there's really one two three four depending on how you count it lines of code and the error rates we're getting are pretty close to state of the art and it takes about 30 seconds to run so this is an image classifier so where does the information come from how do you get the labels from that what transformations do you want to do what normalization do you want to do what kind of model do you want to build what metrics do you want to print out so if we look on the other hand at another fastai.vision example which is segmentation so here's something that is looking at trying to color code every pixel in an image to say whether it's road or sky or building or car or so forth you can see it's the same basic four lines of code and again we can train it and in a few minutes we get basically state-of-the-art results or very close to state-of-the-art results so by carefully designing this api it means that you'd learn the api once for one application then you can use it across other applications so you can see we've got the same basic four lines of code here to train a um in this case it's a text classifier which is predicting uh whether or not this is a positive or negative sentiment so once you've learnt the vision api you already know the text api here's the same basic four lines of code to do a tabular learner this is something that looks at things like csv files and spreadsheets and database tables and this one is predicting um somebody's i think is predicting their income level based on things like their education level and occupation and demographic data so again you know same basic four lines of code for collaborative filtering for recommendations the same again basic four lines of code so this software engineering principle is all about trying to keep things as consistent as possible and if there's differences between apis it should be because they're necessary for um for the domain not because it's just more convenient from an implementation point of view so we try to provide a very um uh consistent picture across all of the different applications of like how to interact with them um to minimize the amount of learning you have to do as you move from problem to problem one of the reasons we were able to build that application api is because it's built on top of this really nice mid tier and the mid-tier api is not something that's designed to just be deep inside the library and that you shouldn't have to worry about we actually carefully document this it's included in the book is how to use it in fact all the layers are because the idea is that if you're a researcher or or whatever and you need to go a little bit deeper on some part of the training process perhaps there's some performance issue for your particular domain that you need to improve or there's something you think you might be able to change to make your accuracy better you should be able to go as deep as you like in that area and try things out and change things and everything above it should continue to work so the mid-tier api um [Music] starts with um uh i'll explain it starting with the uh the training loop and these slides were written by uh sylvan gujjar the this is the basic uh pie torch training loop um to fit a model you go through each epoch for each epoch you go through each independent independent variable of your many batches you make a prediction by calling the model you calculate the loss by calling your loss function with the predictions and the targets you calculate the gradients and then you step the optimizers and reset the optimizers so this is the basic cycle prediction from the model calculate the loss get the radiance gradients do the optimizer step repeat until your model is hopefully really good um but there's a lot of tweaks that in practice you'll always want to add for example you might want to attach to some kind of um tracking system like our own fast progress that you see here or i think this is tensorboard or weights and biases or so forth you're probably going to want to add some kind of parameter scheduler such as sjdr or onecycle you're probably going to want to add various kinds of regularization of which there are countless range that you can try out and then there's more complex things you might want to do such as gans so in practice um what used to happen prior to fast ai was people would generally write a whole new training loop each time and it wasn't just to add one of those features but for each kind of combination of those features you want to try you have to either modify the previous training loop you had or um or create a new training loop and you kind of end up with this whole mess of different approaches which are not consistent with each other and it's so easy to make mistakes and it takes such a long time um in fastai uh the previous version of fast ai this is our training loop we just made a really really big training loop um which tried to incorporate a whole range of different things um and this is what most uh training loops most like library training loops still look like today but we refactored it and so the key uh software engineering principle here is refactoring and in particular adding hooks to allow users including ourself as users of the mid-tier api to modify anything without changing the basic structure using callbacks now a lot of deep learning libraries have some kind of callbacks um but they're generally pretty limited they're generally they can only read information they can only read a subset of information and they can only read that subset of information at a subset of times fast ai is unique in that every every single part of the training process can have zero or more callbacks as many as you like and everyone can access every part of the system and can change every part of the system including changing what happens next they can also describe the relationship between each other and how they should be ordered they're incredibly flexible a really interesting new approach to this so this is our original training loop and so basically with callbacks that trading loop ends up embedded in something that's calling a bunch of callbacks so the training loop is still pretty simple um but it means that everything we've wanted to do and we've done dozens of different things and our users have done thousands of different things um can all be directly done as a little callback uh so for example gradient clipping is where if the gradients get really big you cut them off at some maximum level um so here is something that's after backwards so after the backward pass runs that calculates the gradients um if they if they're using clipping then call the clip gradient norm function passing in the parameters and passing in the amount to clip to so you can see here that we're actually modifying the gradients themselves after they've been calculated just with a single line of code so you can mix these uh different techniques together uh these are a variety of the um you know small number of the huge number of different things that we've added and our user community has added through callbacks and one of the most important things here is that each of these are fully decoupled so you can mix and match them together so you can have lost penalties and gradient accumulation and mix up and one circle training and bomb you just pop them all in and you don't have to think about it it just works so for example um here is the really important uh mix-up technique that was developed a couple of years ago and it's a technique which uh basically takes um uh two images and takes a combination of those two images and a combination of their labels it's a data augmentation technique and as you can see the implementation of mix up as a callback you know it's just a dozen or so lines of code and it runs very quickly on the gpu and can be combined with any of the other callbacks that i mentioned and if you can compare that to the original paper this is the implementation of mix-up in the original mix-up paper it's much longer right and more importantly all of the things that are needed have to be combined into this one function so for example printing out a progress bar and deciding what metrics and so forth they're all coupled in together so this is a really important software engineering principle is the idea of decoupling and allowing these independent decoupled systems to integrate together to create something better than each part alone another example of the mid-tier api is the um the optimizer before fast ai every time somebody wanted to create a new optimizer which is very often optimizers are a rapidly developing area of research they would write it from scratch so for example pytorch has an optimizer called adam w which is actually one of the most useful optimizers around and here is the update step for adam w from the pytorch source code here's the atom w update from fast ai atom w actually is identical to atom but we add in these three lines of code and this one part in gray so it's basically like three and a half lines of code to add and the reason for that was that we spent a lot of time refactoring and it's interesting because when you look at deep learning research papers it turns out that a lot of what gets published is basically um it's basically coming out of refactoring the algorithms um so we actually tried to refactor all the optimization algorithms so we read as many papers as we could and we realized that there was a two basic pieces that if we can combine them together we could describe every optimizer every paper that we could find which we call stats and steppers stats are basically things that keep track of what's going on in the parameters and then steppers are things that use the parameters and the stats to figure out how to update the parameters and by combining these two together we were able to build every modern optimizer that we tried so for example while we were building this um about 18 months ago uh the uh a paper that came out that showed how to reduce the training time for a really important algorithm called burt from three days to 76 minutes using something called a lam optimizer so the key thing was they developed a new optimizer we had it implemented by the end of the day when the paper came out and the entire implementation is one two three four five six seven eight lines of code and more importantly the eight lines of code map really directly to the actual algorithm in the paper so it really helps domain experts to to map their their math understanding directly to code and vice versa this was very different to other libraries which generally took some months to implement the land paper and when they did it would be implemented from scratch as as pages of code um so this is like some questions around this example yeah hit me so uh people want to know can you use these fast ai optimizers and some of these other tools with other libraries somehow or do you have to convert everything to fast ai yeah so one of the important ideas of fast ai software engineering principles is decoupling and so all these things are decoupled there are defined documented apis that each thing needs and it works with that so for example the fastai training loop can be used with any data you have in whatever format you have it and any existing code you have for working with that data and we have actually have examples in the fasta docs that show how to take how to basically take um if you've got some kind of legacy code that's like pure pie torch or catalyst or ignite or you know one of these other training loops we actually show how with no changes to your original code you can start using the fastai training loop with it and generally it's like you add like one or two lines of code and you generally delete 30 or 40 lines of code uh so yeah they they do work very well um you can mix and match very nicely um the more bits of fast ai you use the the more extras you can use so um we'll see some examples of that in a moment um but yeah they're certainly designed to be well decoupled um you mentioned that you implemented this in a day and you also kind of described how you've done a lot of things with just one person or two people full time um you know you developed this vast ecosystem with these software tools like mbdev how do you think that the software tools like mbdev might have just as much impact as deep learning has on uh you know developer generally or what do you feel how do you feel about that um it's a good question i'm not sure um it's possible the the idea of that exploratory programming illiterate programming could result in a kind of explosion in developer productivity has been a hope for decades um and you know even going back to like ivan sutherland um in the 60s there was always this hope that we would you know that people would flock to the idea of tools where they are directly interacting with the environment you know things like small talk were really founded on this principle um for whatever reason that hasn't happened yet and um it kind of feels like coders are i don't know they all seem quite conservative they kind of seem like pretty tied to the idea that text editors should look like text editors and um the the the process of programming should work in a certain way um you know i really admire people like um brett victor and chris latina who have kind of shown us really interesting new ways of doing things um i so i hope yeah i hope that nbdev can help us um move back in that direction um i feel like it's it's there's not enough interest and um momentum towards exploratory programming and real live coding environments um but uh i yeah i think if nb dev can help people move in that direction it could be quite transformational one more question about this um this topic of software engineering so how how important is software engineering when if you're a deep learning practitioner and would you recommend the data scientists rotate through a traditional software engineering role to strengthen their skills in this area um it's a great question um at the moment i'd say yes it probably is very important i'd like it to be not important i'd like it to i'd like all the you know good approaches to be implicitly part of everything we do and that you wouldn't have to learn everything kind of like it's like if you start using nbdev for example you you get continuous integration and hyperlink documentation and all this stuff for free um uh and it's kind of stuff that software engineers are all used to having anyway um but yeah i do think at the moment one of the differences between the most effective deep learning practitioners and data scientists more generally and the rest is how good they are at coding uh including how they're good they are at software engineering more generally so yeah probably i think it's a good thing to spend time practicing and learning about and ideally sitting with experts and learning from them sounds good there's more questions but i'll let you continue okay so um you know another in fact perhaps the most interesting part of the mid-tier api um is the data block api and again this basically came from uh refactoring uh we looked at lots and lots of examples of data processing pipelines that we had built and that that our users had built and realized that all of them actually just handle um four steps um uh which the details don't really matter so much but these are the four steps and so then we created an api where you just say these are the four steps um and it's called the data block api so you say what types of objects do you want to create so i want to create a python imaging library black and white image and a category how do you get the items for those how do you split them into training and validation set and how do you label them and then where does the information come from and then so for example now that we've got that data block we can display a batch of it and you can now see there's the actual pictures of images and there's their category so that's the image black and white and the category so this is one of the key reasons that the the high level api is so consistent across different um applications is that they're all behind the scenes using the data block api so um we can do custom labeling so for example here we're doing prediction of pet breeds we can do multiple labeling and this is quite interesting right for for segmentation we just have to say okay now my to my types are a python imaging library image and a python imaging library mask and all the other steps are basically this are the same but now showbatch automatically will show us segmentation information so we can do the same thing for where's the center of people's face this is a key points problem and you can see the same thing now my independent variable is a python imaging library image and my dependent variable is a tensor representing a point um same thing for object detection uh same thing for text labeling uh and so forth so that mid-tier api depends on the the low level api foundation and one in particular which you might have been getting a sense of in that data blocks examples is object oriented tenses object oriented programming is is not exactly new at this point um but in um every deep learning library uh other than fast eye as fast as far as i'm aware um and this has been gone through a peer review process so i think it's somewhat true every other library a tensor is a tensor it's just a mathematical multi-dimensional array of numbers it has no semantics but fast ai introduces a complete object hierarchy of tensors so there are tenses representing images tenses representing points tensors representing bounding boxes and so forth and so when you say flip left right it it just works regardless of what kind of thing you're flipping for instance and it's really important to have this semantics carried around because because you want to be able to visualize the information you want to be able to make predictions on the information you want to understand what the information is and different types of object also work differently together so you can see here actually we're using a single dispatch uh to also actually we're doing patching here so we're basically inserting this into each of these classes um and then we're calling it um with a single method which will work polymorphically so then we can create for instance a flip item random transform that just calls flip ella and it's going to work for every data type as long as it has a flipala method so this is all obvious stuff for programmers but hasn't existed for tensors before this is the secret to why we can say show batch and get totally different behavior of for example for segmentation we see color-coded pixels whereas for multi-class labeling we see images along with multiple labels um we can even do things like show results which i even highlight in red those where the prediction was different to the actual so again these are tenses that know how to display themselves they don't only know how to display themselves they also know how to display themselves in combination with other types and the way we do that is with multiple dispatch which is basically stolen from julia although i think i first came across the idea when it was developed by damian conway the pearl some decades ago and the idea is that you can say add a type dispatch decorator and say my method has this is the first type will be tensor image and the second type is tensor category and now if you call show results with something of these types it will automatically dispatch to this function and that's the secret to why we can have different things passed in and get totally different visualizations for example another key refactoring was realizing that i guess the refactoring i'm not exactly sure the right description but we basically realized that um a key thing to actually think stuff like visualization working properly and ooh tenses working properly is that you need to be able to undo the transformations that occur in your data processing because to actually pass a tensor to a model it has to be normalized it has to be reshaped it has to be kind of modified in a number of ways that make it quite hard to work with directly so we wanted to be able to undo it so we created a thing called transform which has both an encode which is like how do you what does the transform do but it's also invertible which is decode which is how do you undo it there's a number of other things that turns out that transforms have to be able to do to work effectively as part of a deep learning pipeline and it's a somewhat it's just a little bit different to how normal python functions in python dispatch works but because python is so powerful as a dynamic environment we were able to actually create a new type that has different dispatch and function call behavior in the language itself which is really nice since i'm running a little low on time i won't describe the details and then finally thanks really to pi torch we were able to build uh and to python more generally we're able to build this on a very fast foundation so we built some new parallelization primitives which allowed us to do a lot of the transformation work in parallel in a pretty high performance way without users having to think about it critically and everything possible runs on the gpu even things like image transformations and this is really thanks to pi torch's powerful set of primitives and we build some things on top of that such as uh affine coordinate transforms that allow us to do a really wide range of transformations on the gpu and again the the user the developer doesn't have to think about it they just use the code and you know expect it to not only work but to work fast so i know you said there's some more questions hamill we've got another few minutes so i thought i might finish it um one really popular question is um what is your advice on maintaining models once they're deployed process of retraining versioning redeploying all that stuff you know that tends to be really complicated from a software engineering perspective that people tend to struggle with when they're trying to you know deploy these models into production um yeah um so we've got some comments on that in our book given the time i'm not sure i've got i can i can go into as much detail as i'd like um but basically the key thing for deployment um so there's a few key things one is to keep deployment as simple as possible there's a lot of complexity in deployment around nowadays with things like um you know tensorflow serving or torch serve or whatever and on x all this stuff um i would try to avoid wherever possible all of this serving specific things um and wherever possible try to make your model just a standard um fast ai or pi torch i mean all fast ai models are also pie torch models so it ends up being a standard pie touch model that you just call as a regular python function keep it as simple as possible um run it on the cpu if possible and not the gpu unless you really need to scale for inference um and then so then you can kind of keep a really fast iteration between realizing in production that there's things you want to improve and then experimenting with new approaches and then getting them straight into production quickly you also need to make sure you've got a really good monitoring system that makes really good use of people um so there should be plenty of people that are that are using the things where your model is a part of it people in your organization um trying to find all the ways in which it's doing something that's unexpected or stupid you know trying out out of you know unexpected different kind of data stuff like that but yeah i really think that the key is to try to maximize the the iteration speed and minimize the complexity that makes sense one more question um do you have any advice for people that are wanting to introduce mbdev into their workplace and you know people might not be familiar with fast ai um or have any of that context do you have any advice on how they might be most effective in trying to do that um so i mean it it is a difficult discussion because um nbdev and our whole approach to programming is founded on the idea that um dynamic programming languages like python should be used dynamically so and and jupiter is a great environment to do that kind of work because jupiter gives you actual live objects that you're actually introspecting and working with traditional programming systems don't like vs code and stuff like that um so for people that have spent decades learning a certain way of coding it can seem like wrong you know and and threatening um uh it you know so i think the trick is to try to do it in a small way initially and you know remember with nbdev you can always um with a single button export an actual python library so in a sense nobody need know that you're using nbdev um but yeah maybe then you can kind of say to people like oh you know how i did this quicker than you expected well i use this thing called mbdev and here's how it helped me and look i've even got documentation and tests have all come out of it and so maybe yeah once people can see from a small use case that it's actually been helpful they might help get past the initial skepticism what do you think you introduce a lot of software engineering principles um like you know that are very common here like uh being dry having good defaults so on and so forth what are like the most common things you find missing in in uh big deep learning projects or machine learning projects out there when you look at them and what software engineering principles you think are lacking most often uh i would say refacturing and decoupling you know together so i find um you know at an at an algorithmic level that the the algorithms tend to be implemented in single huge functions um without thinking that like they're actually composed of a number of pieces um and then each kind of paper that gets implemented i think it gets tried tends to be done in this kind of ways like okay let's put all of those things and put it in this project and then there's a different thing we put all of those and put it in this project and so things ended up everything ends up tightly coupled and it really slows down the ability to iterate and experiment and it also really reduces the research insights and kind of performance insights you get because you're not really trying things out independently but just kind of throwing everything together makes sense um we want to be mindful of time how do we have time to keep going i guess we've got done our hour so we should probably wrap up as my guess well thanks thanks so much to both of you uh we have run out of time today i'd just like to thank uh jeremy for his wonderful uh and insightful presentation today and hamel for some expert moderation uh and a special thanks for each and every one of you for taking the time to attend and participate this talk was recorded and will be available online uh in the next day or so and you can check learning.acm.org as well as acm.org on announcements on future tech talks also if you could take a minute to fill out our quick survey where you can suggest future topics or speakers that would be very helpful and you should see that on your screen in a moment on behalf of myself and acm jeremy howard and hamill hussein thanks again to everybody for joining and i hope you'll join again in the future this concludes today's talk you
Show moreFrequently asked questions
What is needed for an electronic signature?
How do I send a document that people can eSign?
How do I sign a document with an electronic signature?
Get more for anneal signature block order with airSlate SignNow
- Real electronically sign
- Prove electronically signed Architectural Proposal Template
- Endorse digisign Service Quote Template
- Authorize electronically sign settlement
- Anneal mark NonProfit Donation Consent
- Justify esign Case Study Proposal Template
- Try countersign Sales Agency Agreement Template
- Add Assignment Agreement digi-sign
- Send Website Quote Template esign
- Fax Letter of Intent for Promotion signature block
- Seal Music Press Release signature
- Password Construction Equipment Lease Proposal Template email signature
- Pass Licensing Agreement signatory
- Renew Divorce Settlement Contract electronically signed
- Test Boy Scout Camp Physical Form byline
- Require Subscription Agreement Template esigning
- Comment proof digital signature
- Boost cosigner countersignature
- Call for successor electronically sign
- Void Amendment to LLC Operating Agreement template digital sign
- Adopt Support Agreement template initial
- Vouch Free Raffle Ticket template signature
- Establish Alabama Bill of Sale template countersignature
- Clear Limousine Service Contract Template template digital signature
- Complete Veterinary Hospital Treatment Sheet template electronically signed
- Force Design Invoice Template template signed
- Permit Income Verification Letter template digi-sign
- Customize Photo Licensing Agreement template esign