Erase Electronic signature Word Simple
Make the most out of your eSignature workflows with airSlate SignNow
Extensive suite of eSignature tools
Robust integration and API capabilities
Advanced security and compliance
Various collaboration tools
Enjoyable and stress-free signing experience
Extensive support
How To Add Sign in eSignPay

Keep your eSignature workflows on track
Our user reviews speak for themselves









Award-winning eSignature solution




Erase Electronic signature Word Simple. Discover probably the most user-pleasant exposure to airSlate SignNow. Deal with your entire papers processing and sharing system digitally. Go from handheld, document-centered and erroneous workflows to automated, electronic digital and flawless. It is simple to make, provide and indication any documents on any system everywhere. Make sure that your essential organization cases don't move overboard.
Learn how to Erase Electronic signature Word Simple. Stick to the easy information to get going:
- Build your airSlate SignNow bank account in click throughs or sign in with your Facebook or Google profile.
- Enjoy the 30-day free trial offer or select a prices program that's excellent for you.
- Discover any legal design, develop on the web fillable kinds and talk about them safely.
- Use innovative functions to Erase Electronic signature Word Simple.
- Signal, modify putting your signature on get and accumulate in-person signatures 10 times speedier.
- Set up automatic reminders and receive notices at each stage.
Transferring your activities into airSlate SignNow is uncomplicated. What practices is a straightforward method to Erase Electronic signature Word Simple, along with tips to maintain your co-workers and partners for greater alliance. Encourage your employees using the best equipment to remain on top of business functions. Boost output and level your organization speedier.
How it works
Rate your experience
-
Best ROI. Our customers achieve an average 7x ROI within the first six months.
-
Scales with your use cases. From SMBs to mid-market, airSlate SignNow delivers results for businesses of all sizes.
-
Intuitive UI and API. Sign and send documents from your apps in minutes.
A smarter way to work: —how to industry sign banking integrate

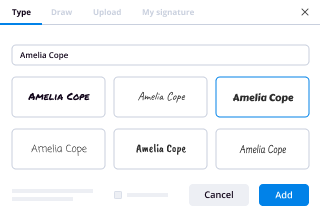
How to eSign & fill out a document online
Document management isn't an easy task. The only thing that makes working with documents simple in today's world, is a comprehensive workflow solution. Signing and editing documents, and filling out forms is a simple task for those who utilize eSignature services. Businesses that have found reliable solutions to functionality electronic signature erase word simple don't need to spend their valuable time and effort on routine and monotonous actions.
Use airSlate SignNow and functionality electronic signature erase word simple online hassle-free today:
- Create your airSlate SignNow profile or use your Google account to sign up.
- Upload a document.
- Work on it; sign it, edit it and add fillable fields to it.
- Select Done and export the sample: send it or save it to your device.
As you can see, there is nothing complicated about filling out and signing documents when you have the right tool. Our advanced editor is great for getting forms and contracts exactly how you want/need them. It has a user-friendly interface and full comprehensibility, offering you complete control. Register right now and start enhancing your eSignature workflows with convenient tools to functionality electronic signature erase word simple online.
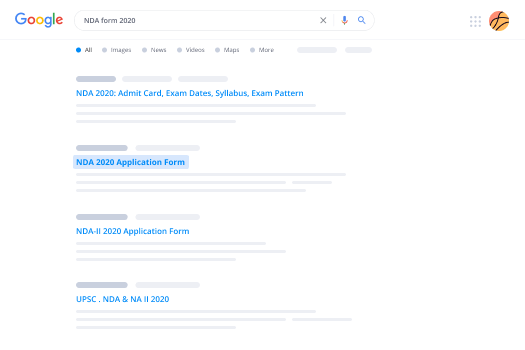
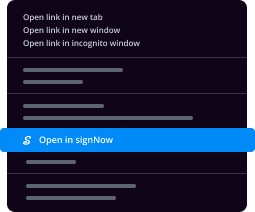
How to eSign and fill documents in Google Chrome
Google Chrome can solve more problems than you can even imagine using powerful tools called 'extensions'. There are thousands you can easily add right to your browser called ‘add-ons’ and each has a unique ability to enhance your workflow. For example, functionality electronic signature erase word simple and edit docs with airSlate SignNow.
To add the airSlate SignNow extension for Google Chrome, follow the next steps:
- Go to Chrome Web Store, type in 'airSlate SignNow' and press enter. Then, hit the Add to Chrome button and wait a few seconds while it installs.
- Find a document that you need to sign, right click it and select airSlate SignNow.
- Edit and sign your document.
- Save your new file to your account, the cloud or your device.
By using this extension, you avoid wasting time on boring actions like saving the data file and importing it to an eSignature solution’s collection. Everything is close at hand, so you can quickly and conveniently functionality electronic signature erase word simple.
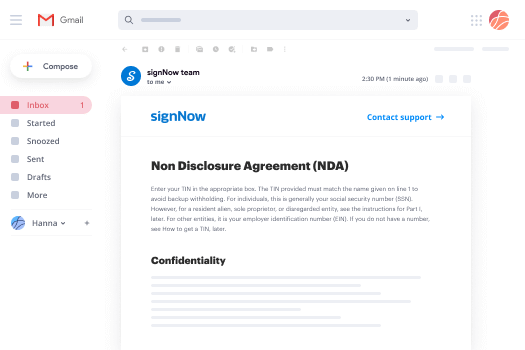
How to eSign forms in Gmail
Gmail is probably the most popular mail service utilized by millions of people all across the world. Most likely, you and your clients also use it for personal and business communication. However, the question on a lot of people’s minds is: how can I functionality electronic signature erase word simple a document that was emailed to me in Gmail? Something amazing has happened that is changing the way business is done. airSlate SignNow and Google have created an impactful add on that lets you functionality electronic signature erase word simple, edit, set signing orders and much more without leaving your inbox.
Boost your workflow with a revolutionary Gmail add on from airSlate SignNow:
- Find the airSlate SignNow extension for Gmail from the Chrome Web Store and install it.
- Go to your inbox and open the email that contains the attachment that needs signing.
- Click the airSlate SignNow icon found in the right-hand toolbar.
- Work on your document; edit it, add fillable fields and even sign it yourself.
- Click Done and email the executed document to the respective parties.
With helpful extensions, manipulations to functionality electronic signature erase word simple various forms are easy. The less time you spend switching browser windows, opening several profiles and scrolling through your internal samples seeking a document is much more time to you for other significant jobs.

How to securely sign documents in a mobile browser
Are you one of the business professionals who’ve decided to go 100% mobile in 2020? If yes, then you really need to make sure you have an effective solution for managing your document workflows from your phone, e.g., functionality electronic signature erase word simple, and edit forms in real time. airSlate SignNow has one of the most exciting tools for mobile users. A web-based application. functionality electronic signature erase word simple instantly from anywhere.
How to securely sign documents in a mobile browser
- Create an airSlate SignNow profile or log in using any web browser on your smartphone or tablet.
- Upload a document from the cloud or internal storage.
- Fill out and sign the sample.
- Tap Done.
- Do anything you need right from your account.
airSlate SignNow takes pride in protecting customer data. Be confident that anything you upload to your account is secured with industry-leading encryption. Automated logging out will shield your account from unauthorised access. functionality electronic signature erase word simple out of your phone or your friend’s mobile phone. Protection is key to our success and yours to mobile workflows.

How to electronically sign a PDF with an iOS device
The iPhone and iPad are powerful gadgets that allow you to work not only from the office but from anywhere in the world. For example, you can finalize and sign documents or functionality electronic signature erase word simple directly on your phone or tablet at the office, at home or even on the beach. iOS offers native features like the Markup tool, though it’s limiting and doesn’t have any automation. Though the airSlate SignNow application for Apple is packed with everything you need for upgrading your document workflow. functionality electronic signature erase word simple, fill out and sign forms on your phone in minutes.
How to sign a PDF on an iPhone
- Go to the AppStore, find the airSlate SignNow app and download it.
- Open the application, log in or create a profile.
- Select + to upload a document from your device or import it from the cloud.
- Fill out the sample and create your electronic signature.
- Click Done to finish the editing and signing session.
When you have this application installed, you don't need to upload a file each time you get it for signing. Just open the document on your iPhone, click the Share icon and select the Sign with airSlate SignNow button. Your sample will be opened in the mobile app. functionality electronic signature erase word simple anything. Additionally, utilizing one service for your document management demands, things are easier, smoother and cheaper Download the app today!

How to eSign a PDF document on an Android
What’s the number one rule for handling document workflows in 2020? Avoid paper chaos. Get rid of the printers, scanners and bundlers curriers. All of it! Take a new approach and manage, functionality electronic signature erase word simple, and organize your records 100% paperless and 100% mobile. You only need three things; a phone/tablet, internet connection and the airSlate SignNow app for Android. Using the app, create, functionality electronic signature erase word simple and execute documents right from your smartphone or tablet.
How to sign a PDF on an Android
- In the Google Play Market, search for and install the airSlate SignNow application.
- Open the program and log into your account or make one if you don’t have one already.
- Upload a document from the cloud or your device.
- Click on the opened document and start working on it. Edit it, add fillable fields and signature fields.
- Once you’ve finished, click Done and send the document to the other parties involved or download it to the cloud or your device.
airSlate SignNow allows you to sign documents and manage tasks like functionality electronic signature erase word simple with ease. In addition, the security of your information is top priority. File encryption and private servers can be used for implementing the most recent functions in info compliance measures. Get the airSlate SignNow mobile experience and work more efficiently.






FAQs
-
What is a black hole, for those of us not versed in astronomy and physics?
I will answer this question in four parts:What is a black hole?How is a black hole formed?Why does a black hole have such an intense gravitational field?What is the anatomy of a black hole?What is a black hole?A black hole is a location in space with such a strong gravitational field that the escape velocity exceeds the speed of light. What this means is that you require a velocity greater than the speed of light (a physical impossibility) to escape the black hole, as can be seen in the image below.Image credit: Frigg MnSU Astronomy GroupAs no light can escape a black hole, it’s black. Not black like your shirt, which does reflect light. No, since a black hole reflects no light at all, it’s as black as can be.The image below is a nice analogy for a black hole, where, beyond a certain point, the water current is so strong that no speed will be sufficient to escape it.Image credit: Answers magazineThis is really quite a perfect analogy, because while we cannot study black holes directly since we cannot observe them or look inside them (we can only deduce their presence from their gravitational field which influences stars around them, and we can see radiation from infalling matter), we can study black hole analogues, and one such analogue to study Hawking radiation (a process by which black holes are thought to slowly evaporate) makes use of water currents:The Black Hole Machine – Sixty SymbolsHow is a black hole formed?It all starts with a massive star. As the star fuses hydrogen into heavier elements (a process called thermonuclear fusion), the heat produced creates an outward pressure, which acts against the inward force from gravity. In essence, the thermal pressure prevents the star from collapsing under its own gravity, and as long as the star has fuel to fuse and create heat, the thermal pressure and gravity are in balance (called hydrostatic equilibrium).Image: Copyright © 2017 Martin Silvertant. All Rights Reserved.At one point the star runs out of fuel, which means the thermal pressure decreases, and gravity takes over. This is when a core collapse occurs. Stars with an end mass below the Chandrasekhar limit of 1.4 times the mass of the Sun will collapse into white dwarfs, stars with an end mass between the Chandrasekhar limit and the Tolman–Oppenheimer–Volkoff limit (TOV limit) of 2–3 times the mass of the Sun will become neutron stars, and stars with an end mass above the TOV limit will become black holes. This end mass correlates with an initial mass of at least 25 times the mass of the Sun.Let’s say the star in the image above is 30 solar masses. When the core collapses, an explosion occurs called a supernova, which ejects a lot of the material into space. Here is an image of an actual supernova:Image credit: NASA’s Chandra X-ray ObservatoryIn the image below you can see how the initial mass of a star relates to its end mass. For a star with an initial mass 30 times the mass of the Sun, its end mass is around 4 solar masses—enough to form a black hole.Image credit: Marco LimongiI marked two lines in the image as examples on how to read it. A star with an initial mass of 25 M☉ (solar masses) will have an end mass of around 2 M☉ (remember the TOV limit of 2–3 M☉?). I also marked a star of 30 M☉ in blue, which as you can see corresponds to an end mass of 4 M☉. Also, as you can see any star with an initial mass below 25 M☉ will become a neutron star with a mass of 0.88–1.44 M☉[1].Why does a black hole have such an intense gravitational field?Now, here comes the crucial bit. The strength of a gravitational field depends on two factors:The mass of an object.How far away you are from the object.Image: Copyright © 2017 Martin Silvertant. All Rights Reserved.If you look at the star above, it has a much bigger radius than the neutron star and the black hole. The proportions are way off however, as the neutron star and black hole are far smaller than this. While the Sun has a diameter of 1.3914 million km (and 1 solar mass), a neutron star is typically about 20 km in diameter (at around 1.4 solar masses), and a black hole with a mass of 3 solar masses is thought to be compressed to a point, though its Schwarzschild radius (or gravitational radius) at this mass is around 8.86 km (17.73 km in diameter). I will talk more about the Schwarzschild radius in a moment.So here you have three objects of increasing mass, but decreasing radius. Now, although all three objects have gravitational fields of different strengths due to differences in mass, their radius is also crucial. If we assume all three objects to be of the same mass but different sizes, then in order to experience the same gravitational field from the star as from the neutron star, you would have to be inside the star. However, to experience the same gravitational field from the neutron star as from the regular star, you can be a long distance away from it (indicated by the yellow circle around the neutron star). So you see, given the same mass but a smaller radius, you can get much closer to the neutron star as you could to the regular star, and so you would experience a far more intense gravitational field on the surface of the neutron star as on the regular star. A black hole has more mass and a far smaller radius (presumed to be a point source), so its gravitational field when you get close to it is really extreme. Extreme enough so that not even light—which has the greatest speed possible in the universe—can escape, as we saw at the beginning.What is the anatomy of a black hole?Now for the fun bit. What are the components of the black hole? Below you can see a simplified version of the relevant parts of a black hole. First of all, we talked about how a black hole is compressed to a point. At least, this is what is supposed, though in reality we really don’t know if a black hole is actually a point source. Whether this point source is physical or mathematical, it’s called a gravitational singularity. This singularity has a region within which the escape velocity exceeds the speed of light, defined by the Schwarzschild radius. The boundary beyond which not even light can escape the black hole is called the event horizon, which is a boundary in spacetime.Image: Copyright © 2017 Martin Silvertant. All Rights Reserved.Mass curves spacetime, and in case of a black hole the mass density curves spacetime to such an extent that light becomes trapped. The image below gives some idea of what that is like, though do keep in mind that this is a twodimensional representation of the warping of space, whereas in reality space is warped threedimensionally. Therefore it’s better to think of spacetime curving inwards, creating a gravity well (pictured in b in the image below).Ready for more technical stuff? Let’s look at a more complete picture of the black hole anatomy. Below is a Schwarzschild black hole, which is the most general black hole model. It’s a non-rotating black hole without charge. No non-rotating black holes are thought to exist, but the Schwarzschild metric provides a simple model of what’s going on in a black hole. In a moment we will have a look at a rotating black hole.Image: Copyright © 2017 Martin Silvertant. All Rights Reserved.As you can see, there are two to three additional components compared to the basic black hole anatomy. A black hole has an outer event horizon, and an inner event horizon, or Cauchy horizon. One side of the Cauchy horizon contains closed space-like geodesics, and the other side contains closed time-like geodesics. A geodesic is the shortest path between two points in a curved space. As matter falls into the black hole, it takes the shortest possible path, and beyond the Cauchy horizon space- and time geodesics become reversed. So beyond the inner event horizon, you are no longer traveling through space, but through time. As such, if you were to cross this horizon, you would move towards your inevitable future which is the singularity.Outside the Schwarzschild radius, there is a boundary called the photon sphere, where gravity is strong enough that photons (light particles) are forced to travel in orbits. Beyond that boundary and you will move towards the event horizon, but at the photon sphere, photons will travel in orbits for at least a little while (the orbits are unstable). What’s interesting about photons orbiting in circles is that when you are located at the photon sphere, photons that start at the back of your head will orbit the black hole, and will then be captured by your eyes, so effectively you will see the back of your head. Weird stuff.And finally, let’s have a look at a rotating black hole, which is either a Kerr black hole (a rotating black hole without electric charge) or a Kerr–Newman black hole (a rotating black hole with electric charge). A black hole can only have three fundamental properties: mass, electric charge and angular momentum (spin).Image: Copyright © 2017 Martin Silvertant. All Rights Reserved.Stars rotate, and when a massive star collapses into a black hole, its angular momentum is not only conserved in the black hole, but as its radius decreases considerably, so too will its angular momentum increase. Think of an ice skater, who increases its spin rate when she pulls in her arms, which decreases her moment of inertia.Image credit: BoundlessThe rotation of the black hole causes the Schwarzschild radius to become oblate due to the centrifugal force. Also, the gravitational singularity is no longer a point source, but a twodimensional ring singularity. One important additional component to a rotating black hole is the ergosphere, which is a region beyond the outer event horizon. The ergosphere touches the event horizon at the poles of a rotating black hole and extends to a greater radius at the equator, and depending on the speed of rotation of the black hole, the ergosphere will be shaped either like an oblate spheroid or a pumpkin shape.As a black hole rotates, it twists spacetime in the direction of rotation at a speed that decreases with distance from the event horizon, meaning that spacetime closer to the event horizon will be twisted to a greater degree than the space further out from the event horizon. This process is known as the frame-dragging. Because of this dragging effect, objects within the ergosphere cannot appear stationary with respect to an outside observer at a great distance unless the object was to move at faster than the speed of light with respect to the local spacetime, which is not possible. Since the ergosphere is located outside the event horizon however, objects in this region can still escape from the black hole by gaining velocity due to the rotation of the black hole.So that’s basically what a black hole is. There is a lot more to be said about black holes, but this covers a lot of the basics. Now that you understand a lot of the basics, consider reading the following answer for complementary information:Martin Silvertant’s answer to Can you tell me about black holes?Footnotes[1] [astro-ph/0012321] On the minimum and maximum mass of neutron stars and the delayed collapse
-
What is a registered exporter system (REX)?
In Simple Words REX is Compliance system initiated by European union for Certification of Origin.If one wants to export goods value exceeds 6000 EUR to Europe then has to attach this certificate with consignment.In Official Frame of words:Subject: – Certification of Origin of Goods for European Union Generalised System of Preferences (EU-GSP) – Modification of the system as of 1 January 2017.In exercise of powers conferred under paragraph 2.04 of the Foreign Trade Policy, 2015-2020, the Director General of Foreign Trade hereby inserts a new sub para (c) under Para 2.104 Generalised System o...
-
What is big data and how do I learn about it?
What is big data and how do I learn about it?Big Data is defined by the three V’s:Volume—large amounts of data;Variety—the data comes in different forms, including traditional databases, images, documents, and complex records;Velocity—the content of the data is constantly changing through the absorption of complementary data collections, the introduction of previously archived data or legacy collections, and from streamed data arriving from multiple sources.It is important to distinguish Big Data from “lots of data” or “massive data.” In a Big Data Resource, all three V’s must apply. It is the size, complexity, and restlessness of Big Data resources that account for the methods by which these resources are designed, operated, and analyzed.The term “lots of data” is often applied to enormous collections of simple-format records. For example every observed star, its magnitude and its location; the name and cell phone number of every person living in the United States; and the contents of the Web.These very large datasets are sometimes just glorified lists. Some “lots of data” collections are spreadsheets (2-dimensional tables of columns and rows), so large that we may never see where they end.Big Data resources are not equivalent to large spreadsheets, and a Big Data resource is never analyzed in its totality. Big Data analysis is a multi-step process whereby data is extracted, filtered, and transformed, with analysis often proceeding in a piecemeal, sometimes recursive, fashion. As you read this book, you will find that the gulf between “lots of data” and Big Data is profound; the two subjects can seldom be discussed productively within the same venue.Big Data Versus Small DataActually, the main function of Big Science is to generate massive amounts of reliable and easily accessible data... Insight, understanding, and scientific progress are generally achieved by ‘small science.’Big Data is not small data that has become bloated to the point that it can no longer fit on a spreadsheet, nor is it a database that happens to be very large. Nonetheless, some professionals who customarily work with relatively small data sets, harbor the false impression that they can apply their spreadsheet and database know-how directly to Big Data resources without attaining new skills or adjusting to new analytic paradigms.As they see things, when the data gets bigger, only the computer must adjust (by getting faster, acquiring more volatile memory, and increasing its storage capabilities); Big Data poses no special problems that a supercomputer could not solve. More information please refer to the Office 2019 Guide.This attitude, which seems to be prevalent among database managers, programmers, and statisticians, is highly counterproductive. It will lead to slow and ineffective software, huge investment losses, bad analyses, and the production of useless and irreversibly defective Big Data resources.Let us look at a few of the general differences that can help distinguish Big Data and small data. – Goals small data—Usually designed to answer a specific question or serve a particular goal. Big Data—Usually designed with a goal in mind, but the goal is flexible and the questions posed are protean.Here is a short, imaginary funding announcement for Big Data grants designed “to combine high-quality data from fisheries, coast guard, commercial shipping, and coastal management agencies for a growing data collection that can be used to support a variety of governmental and commercial management studies in the Lower Peninsula.”In this fictitious case, there is a vague goal, but it is obvious that there really is no way to completely specify what the Big Data resource will contain, how the various types of data held in the resource will be organized, connected to other data resources, or usefully analyzed. Nobody can specify, with any degree of confidence, the ultimate destiny of any Big Data project; it usually comes as a surprise.– Locationsmall data—Typically, contained within one institution, often on one computer, sometimes in one file.Big Data—Spread throughout electronic space and typically parceled onto multiple Internet servers, located anywhere on earth.– Data structure and content small data—Ordinarily contains highly structured data. The data domain is restricted to a single discipline or sub-discipline. The data often comes in the form of uniform records in an ordered spreadsheet.PRINCIPLES AND PRACTICE OF BIG DATABig Data—Must be capable of absorbing unstructured data (e.g., such as free-text documents, images, motion pictures, sound recordings, physical objects). The subject matter of the resource may cross multiple disciplines, and the individual data objects in the resource may link to data contained in other, seemingly unrelated, Big Data resources.– Data preparationsmall data—In many cases, the data user prepares her own data, for her own purposes. Big Data—The data comes from many diverse sources, and it is prepared by many people. The people who use the data are seldom the people who have prepared the data.– Longevitysmall data—When the data project ends, the data is kept for a limited time (seldom longer than 7 years, the traditional academic life-span for research data); and then discarded.Big Data—Big Data projects typically contain data that must be stored in perpetuity. Ideally, the data stored in a Big Data resource will be absorbed into other data resources. Many Big Data projects extend into the future and the past (e.g., legacy data), accruing data prospectively and retrospectively.– Measurementssmall data—Typically, the data is measured using one experimental protocol, and the data can be represented using one set of standard units.Big Data—Many different types of data are delivered in many different electronic formats. Measurements, when present, may be obtained by many different protocols. Verifying the quality of Big Data is one of the most difficult tasks for data managers. [Glossary Data Quality Act]– Reproducibilitysmall data—Projects are typically reproducible. If there is some question about the quality of the data, the reproducibility of the data, or the validity of the conclusions drawn from the data, the entire project can be repeated, yielding a new data set.Big Data—Replication of a Big Data project is seldom feasible. In general, the most that anyone can hope for is that bad data in a Big Data resource will be found and flagged as such.– Stakessmall data—Project costs are limited. Laboratories and institutions can usually recover from the occasional small data failure.Big Data—Big Data projects can be obscenely expensive. A failed Big Data effort can lead to bankruptcy, institutional collapse, mass firings, and the sudden disintegration of all the data held in the resource. As an example, a United States National Institutes of Health Big Data project known as the “NCI cancer biomedical informatics grid” cost at least $350 million for fiscal years 2004–10.An ad hoc committee reviewing the resource found that despite the intense efforts of hundreds of cancer researchers and information specialists, it had accomplished so little and at so great an expense that a project moratorium was called.Soon thereafter, the resource was terminated. Though the costs of failure can be high, in terms of money, time, and labor, Big Data failures may have some redeeming value. Each failed effort lives on as intellectual remnants consumed by the next Big Data effort.– Introspectionsmall data—Individual data points are identified by their row and column location within a spreadsheet or database table. If you know the row and column headers, you can find and specify all of the data points contained within.Big Data—Unless the Big Data resource is exceptionally well designed, the contents and organization of the resource can be inscrutable, even to the data managers. Complete access to data, information about the data values, and information about the organization of the data are achieved through a technique herein referred to as introspection.– Analysissmall data—In most instances, all of the data contained in the data project can be analyzed together, and all at once.Big Data—With few exceptions, such as those conducted on supercomputers or in parallel on multiple computers, Big Data is ordinarily analyzed in incremental steps. The data are extracted, reviewed, reduced, normalized, transformed, visualized, interpreted, and re-analyzed using a collection of specialized methods.Whence Comest Big Data?Often, the impetus for Big Data is entirely ad hoc. Companies and agencies are forced to store and retrieve huge amounts of collected data (whether they want to or not). Generally, Big Data comes into existence through any of several different mechanisms:– An entity has collected a lot of data in the course of its normal activities and seeks to organize the data so that materials can be retrieved, as needed.The Big Data effort is intended to streamline the regular activities of the entity. In this case, the data is just waiting to be used. The entity is not looking to discover anything or to do anything new. It simply wants to use the data to accomplish what it has always been doing;only better. The typical medical center is a good example of an “accidental” Big Data resource. The day-to-day activities of caring for patients and recording data into hospital information systems results in terabytes of collected data, in forms such as laboratory reports, pharmacy orders, clinical encounters, and billing data.Most of this information is generated for one-time specific use (e.g., supporting a clinical decision, collecting payments for a procedure). It occurs to the administrative staff that the collected data can be used, in its totality, to achieve mandated goals: improving the quality of service, increasing staff efficiency, and reducing operational costs.– An entity has collected a lot of data in the course of its normal activities and decides that there are many new activities that could be supported by their data.Consider modern corporations; these entities do not restrict themselves to one manufacturing process or one target audience. They are constantly looking for new opportunities.Their collected data may enable them to develop new products based on the preferences of their loyal customers, to signNow new markets, or to market and distribute items via the Web. These entities will become hybrid Big Data/manufacturing enterprises.– An entity plans a business model based on a Big Data resource.Unlike the previous examples, this entity starts with Big Data and adds a physical component secondarily. Amazon and FedEx may fall into this category, as they began with a plan for providing a data-intense service (e.g., the Amazon Web catalog and the FedEx package tracking system).The traditional tasks of warehousing, inventory, pick-up, and delivery had been available all along but lacked the novelty and efficiency afforded by Big Data.– An entity is part of a group of entities that have large data resources, all of whom understand that it would be to their mutual advantage to federate their data resources.An example of a federated Big Data resource would be hospital databases that share electronic medical health records.– An entity with skills and vision develops a project wherein large amounts of data are collected and organized, to the benefit of themselves and their user-clients.An example would be a massive online library service, such as the U.S. National Library of Medicine’s PubMed catalog, or the Google Books collection.– An entity has no data and has no particular expertise in Big Data technologies, but it has money and vision.The entity seeks to fund and coordinate a group of data creators and data holders, who will build a Big Data resource that can be used by others. Government agencies have been the major benefactors. These Big Data projects are justified if they lead to important discoveries that could not be attained at a lesser cost with smaller data resources.The Most Common Purpose of Big Data Is to Produce Small DataIf I had known what it would be like to have it all, I might have been willing to settle for less.Imagine using a restaurant locater on your smartphone. With a few taps, it lists the Italian restaurants located within a 10-block radius of your current location.The database being queried is big and complex (a map database, a collection of all the restaurants in the world, their longitudes and latitudes, their street addresses, and a set of ratings provided by patrons, updated continuously), but the data that it yields is small (e.g., five restaurants, marked on a street map, with pop-ups indicating their exact address, telephone number, and ratings). Your task comes down to selecting one restaurant from among the five, and dining thereat.In this example, your data selection was drawn from a large data set, but your ultimate analysis was confined to a small data set (i.e., five restaurants meeting your search criteria). The purpose of the Big Data resource was to proffer the small data set. No analytic work was performed on the Big Data resource; just search and retrieval.The real labor of the Big Data resource involved collecting and organizing complex data so that the resource would be ready for your query. Along the way, the data creators had many decisions to make (e.g., Should bars be counted as restaurants? What about takeaway only shops? What data should be collected? How should missing data be handled? How will data be kept current?Big Data is seldom if ever, analyzed in toto. There is almost always a drastic filtering process that reduces Big Data into smaller data. This rule applies to scientific analyses. The Australian Square Kilometre Array of radio telescopes [8], WorldWide Telescope, CERN’s Large Hadron Collider and the Pan-STARRS (Panoramic Survey Telescope and Rapid Response System) array of telescopes produce petabytes of data every day. Researchers use these raw data sources to produce much smaller data sets for analysis [9].Here is an example showing how workable subsets of data are prepared from Big Data resources. Blazars are rare super-massive black holes that release jets of energy that move at near-light speeds. Cosmologists want to know as much as they can about these strange objects. A first step to studying blazars is to locate as many of these objects as possible.Afterward, various measurements on all of the collected blazars can be compared, and their general characteristics can be determined. Blazars seem to have a gamma ray signature that is not present in other celestial objects. The WISE survey collected infrared data on the entire observable universe.Researchers extracted from the Wise data every celestial body associated with an infrared signature in the gamma-ray range that was suggestive of blazars; about 300 objects. Further research on these 300 objects led the researchers to believe that about half were blazars [10]. This is how Big Data research often works; by constructing small data sets that can be productively analyzed.Because a common role of Big Data is to produce small data, a question that data managers must ask themselves is: “Have I prepared my Big Data resource in a manner that helps it become a useful source of small data?”Big Data Sits at the Center of the Research UniverseIn the past, scientists followed a well-trodden path toward truth: hypothesis, then experiment, then data, then analysis, then publication. The manner in which a scientist analyzed his or her data was crucial because other scientists would not have access to the same data and could not re-analyze the data for themselves.Basically, the results and conclusions described in the manuscript was the scientific product. The primary data upon which the results and conclusion were based (other than one or two summarizing tables) were not made available for review. Scientific knowledge was built on trust. Customarily, the data would be held for 7 years, and then discarded.In the Big data paradigm, the concept of a final manuscript has little meaning. Big Data resources are permanent, and the data within the resource is immutable. Any scientist’s analysis of the data does not need to be the final word; another scientist can access and re-analyze the same data over and over again.Original conclusions can be validated or discredited. New conclusions can be developed. The centerpiece of science has moved from the manuscript, whose conclusions are tentative until validated, to the Big Data resource, whose data will be tapped repeatedly to validate old manuscripts and spawn new manuscripts.Today, hundreds or thousands of individuals might contribute to a Big Data resource. The data in the resource might inspire dozens of major scientific projects, hundreds of manuscripts, thousands of analytic efforts, and millions or billions of search and retrieval operations. The Big Data resource has become the central, massive object around which universities, research laboratories, corporations, and federal agencies orbit.These orbiting objects draw information from the Big Data resource, and they use the information to support analytic studies and to publish manuscripts. Because Big Data resources are permanent, any analysis can be critically examined using the same set of data, or re-analyzed anytime in the future. Because Big Data resources are constantly growing forward in time (i.e., accruing new information) and backward in time (i.e., absorbing legacy data sets), the value of the data is constantly increasing.Big Data resources are the stars of the modern information universe. All matter in the physical universe comes from heavy elements created inside stars, from lighter elements.All data in the informational universe is complex data built from simple data. Just as stars can exhaust themselves, explode, or even collapse under their own weight to become black holes; Big Data resources can lose funding and die, release their contents and burst into nothingness, or collapse under their own weight, sucking everything around them into a dark void. It is an interesting metaphor.GlossaryBig Data resource A Big Data collection that is accessible for analysis. Readers should understand that there are collections of Big Data (i.e., data sources that are large, complex, and actively growing) that are not designed to support analysis; hence, not Big Data resources.Such Big Data collections might include some of the older hospital information systems, which were designed to deliver individual patient records upon request; but could not support projects wherein all of the data contained in all of the records were opened for selection and analysis. Aside from privacy and security issues, opening a hospital information system to these kinds of analyses would place enormous computational stress on the systems (i.e., produce system crashes).In the late 1990s and the early 2000s, data warehousing was popular. Large organizations would collect all of the digital information created within their institutions, and these data were stored as Big Data collections, called data warehouses. If an authorized person within the institution needed some specific set of information (e.g., emails sent or received in February 2003; all of the bills paid in November 1999), it could be found somewhere within the warehouse.For the most part, these data warehouses were not true Big Data resources because they were not organized to support a full analysis of all of the contained data. Another type of Big Data collection that may or may not be considered a Big Data resource are compilations of scientific data that are accessible for analysis by private concerns, but closed for analysis by the public.In this case, a scientist may make a discovery based on her analysis of a private Big Data collection, but the research data is not open for critical review. In the opinion of some scientists, including myself, if the results of data analysis are not available for review, then the analysis is illegitimate. Of course, this opinion is not universally shared, and Big Data professionals hold various definitions for a Big Data resource.ConclusionsConclusions are the interpretations made by studying the results of an experiment or a set of observations. The term “results” should never be used interchangeably with the term “conclusions.” Remember, results are verified. Conclusions are validated.Data Quality Act In the United States the data upon which public policy is based must have quality and must be available for review by the public. Simply put, public policy must be based on verifiable data. The Data Quality Act of 2002 requires the Office of Management and Budget to develop government-wide standards for data quality.Data manager This book uses “data manager” as a catchall term, without attaching any specific meaning to the name. Depending on the institutional and cultural milieu, synonyms and plesionyms (i.e., near-synonyms) for data manager would include technical lead, team liaison, data quality manager, chief curator, chief of operations, project manager, group supervisor, and so on.Data resource A collection of data made available for data retrieval. The data can be distributed over servers located anywhere on earth or in space. The resource can be static (i.e., having a fixed set of data), or in flux. Pseudonyms for data resource is a data warehouse, data repository, data archive, and data store.Database A software application designed specifically to create and retrieve large numbers of data records (e.g., millions or billions). The data records of a database are persistent, meaning that the application can be turned off, then on, and all the collected data will be available to the user.Grid A collection of computers and computer resources (typically networked servers) that are coordinated to provide the desired functionality. In the most advanced Grid computing architecture, requests can be broken into computational tasks that are processed in parallel on multiple computers and transparently (from the client’s perspective) assembled and returned. The Grid is the intellectual predecessor of Cloud computing. Cloud computing is less physically and administratively restricted than Grid computing.ImmutabilityImmutability is the principle that data collected in a Big Data resource is permanent and can never be modified. At first thought, it would seem that immutability is a ridiculous and impossible constraint. In the real world, mistakes are made, information changes, and the methods for describing information changes. This is all true, but the astute Big Data manager knows how to accrue informa-tion into data objects without changing the pre-existing data.IntrospectionWell-designed Big Data resources support introspection, a method whereby data objects within the resource can be interrogated to yield their properties, values, and class membership. Through introspection, the relationships among the data objects in the Big Data resource can be examined and the structure of the resource can be determined. Introspection is the method by which a data user can find everything there is to know about a Big Data resource without downloading the complete resource.Large Hadron Collider The Large Hadron Collider is the world’s largest and most powerful particle accelerator and is expected to produce about 15 petabytes (15 million gigabytes) of data annually.Legacy data Data collected by an information system that has been replaced by a newer system, and which cannot be immediately integrated into the newer system’s database. For example, hospitals regularly replace their hospital information systems with new systems that promise greater efficiencies, expanded services, or improved interoperability with other information systems. In many cases, the new system cannot readily integrate the data collected from the older system.The previously collected data becomes a legacy to the new system. In such cases, legacy data is simply “stored” for some arbitrary period of time in case someone actually needs to retrieve any of the legacy data.After a decade or so the hospital may find itself without any staff members who are capable of locating the storage site of the legacy data, or moving the data into a modern operating system, or interpreting the stored data, or retrieving appropriate data records, or producing a usable query output.MapReduceA method by which computationally intensive problems can be processed on multiple computers, in parallel. The method can be divided into a mapping step and a reducing step.In the mapping step, a master computer divides a problem into smaller problems that are distributed to other computers. In the reducing step, the master computer collects the output from the other computers. Although MapReduce is intended for Big Data resources and can hold petabytes of data, most Big Data problems do not require MapReduce.Missing data Most complex data sets have missing data values. Somewhere along the line data elements were not entered, records were lost, or some systemic error produced empty data fields. Big Data, being large, complex, and composed of data objects collected from diverse sources, is almost certain to have missing data.Various mathematical approaches to missing data have been developed; commonly involving assigning values on a statistical basis; so-called imputation methods. The underlying assumption for such methods is that missing data arise at random. When missing data arises non-randomly, there is no satisfactory statistical fix.The Big Data curator must track down the source of the errors and somehow rectify the situation. In either case, the issue of missing data introduces a potential bias and it is crucial to fully document the method by which missing data is handled. In the realm of clinical trials, only a minority of data analyses bothers to describe their chosen method for handling missing data.MutabilityMutability refers to the ability to alter the data held in a data object or to change the identity of a data object. Serious Big Data is not mutable. Data can be added, but data cannot be erased or altered. Big Data resources that are mutable cannot establish a sensible data identification system, and cannot support verification and validation activities.The legitimate ways in which we can record the changes that occur in unique data objects (e.g., humans) over time, without ever changing the key/value data attached to the unique object.For programmers, it is important to distinguish data mutability from object mutability, as it applies in Python and other object-oriented programming languages. Python has two immutable objects: strings and tuples.Intuitively, we would probably guess that the contents of a string object cannot be changed, and the contents of a tuple object cannot be changed. This is not the case. Immutability, for programmers, means that there are no methods available to the object by which the contents of the object can be altered.Specifically, a Python tuple object would have no methods it could call to change its own contents. However, a tuple may contain a list, and lists are mutable. For example, a list may have an append method that will add an item to the list object. You can change the contents of a list contained in a tuple object without violating the tuple’s immutability.Parallel computing Some computational tasks can be broken down and distributed to other computers, to be calculated “in parallel.” The method of parallel programming allows a collection of desktop computers to complete intensive calculations of the sort that would ordinarily require the aid of a super-computer.Parallel programming has been studied as a practical way to deal with the higher computational demands brought by Big Data. Although there are many important problems that require parallel computing, the vast majority of Big Data analyses can be easily accomplished with a single, off-the-shelf personal computer.Protocol A set of instructions, policies, or fully described procedures for accomplishing a service, operation, or task. Protocols are fundamental to Big Data. Data is generated and collected according to protocols. There are protocols for conducting experiments, and there are protocols for measuring the results.There are protocols for choosing the human subjects included in a clinical trial, and there are protocols for interacting with the human subjects during the course of the trial. All network communications are conducted via protocols; the Internet operates under a protocol (TCP-IP, Transmission Control Protocol-Internet Protocol).Query The term “query” usually refers to a request, sent to a database, for information (e.g., Web pages, documents, lines of text, images) that matches a provided word or phrase (i.e., the query term). More generally a query is a parameter or set of parameters that are submitted as input to a computer program that searches a data collection for items that match or bear some relationship to the query parameters.In the context of Big Data, the user may need to find classes of objects that have properties relevant to a particular area of interest. In this case, the query is basically introspective, and the output may yield metadata describing individual objects, classes of objects, or the relationships among objects that share particular properties.For example, “weight” may be a property, and this property may fall into the domain of several different classes of data objects. The user might want to know the names of the classes of objects that have the “weight” property and the numbers of object instances in each class.Eventually, the user might want to select several of these classes (e.g., including dogs and cats, but excluding microwave ovens) along with the data object instances whose weights fall within a specified range (e.g., 20–30 pound). This approach to querying could work with any data set that has been well specified with metadata, but it is particularly important when using Big Data resources.Raw data Raw data is the unprocessed, original data measurement, coming straight from the instrument to the database with no intervening interference or modification. In reality, scientists seldom, if ever, work with raw data.When an instrument registers the amount of fluorescence emitted by a hybridization spot on a gene array, or the concentration of sodium in the blood, or virtually any of the measurement that we receive as numeric quantities, the output is produced by an algorithm executed by the measurement instrument.Pre-processing of data is commonplace in the universe of Big Data, and data managers should not labor under the false impression that the data received is “raw,” simply because the data has not been modified by the person who submits the data.Results The term “results” is often confused with the term “conclusions.” Interchanging the two concepts is a source of confusion among data scientists. In the strictest sense, “results” consist of the full set of experimental data collected by measurements. In practice, “results” are provided as a small subset of data distilled from the raw, original data.In a typical journal article, selected data subsets are packaged as a chart or graph that emphasizes some point of interest. Hence, the term “results” may refer, erroneously, to subsets of the original data, or to visual graphics intended to summarize the original data. Conclusions are the inferences drawn from the results. Results are verified; conclusions are validated.Science, Of course, there are many different definitions of science, and inquisitive students should be encouraged to find a conceptualization of science that suits their own intellectual development. For me, science is all about finding general relationships among objects.In the so-called physical sciences the most important relationships are expressed as mathematical equations (e.g., the relationship between force, mass, and acceleration; the relationship between voltage, current, and resistance). In the so-called natural sciences, relationships are often expressed through classifications (e.g., the classification of living organisms).Scientific advancement is the discovery of new relationships or the discovery of a generalization that applies to objects hitherto confined within disparate scientific realms (e.g., evolutionary theory arising from observations of organisms and geologic strata). Engineering would be the area of science wherein scientific relationships are exploited to build new technology.Square Kilometer Array The Square Kilometer Array is designed to collect data from millions of connected radio telescopes and is expected to produce more than one exabyte (1 billion gigabytes) every day.
Trusted esignature solution— what our customers are saying







Get legally-binding signatures now!
Related searches to Erase Electronic signature Word Simple
Frequently asked questions
How do i add an electronic signature to a word document?
How to create an electronic signature in paint?
Pdf how to sign up for veterans medical benefits?
Get more for Erase Electronic signature Word Simple
- How Do I Electronic signature Louisiana Sports PPT
- Help Me With Electronic signature Louisiana Sports PPT
- How Can I Electronic signature Louisiana Sports PPT
- Can I Electronic signature Louisiana Sports PPT
- How To Electronic signature Louisiana Sports PPT
- How Do I Electronic signature Louisiana Sports PPT
- Help Me With Electronic signature Louisiana Sports PPT
- How Can I Electronic signature Louisiana Sports PPT
Find out other Erase Electronic signature Word Simple
- Dts lost receipt form
- 1351 5 form
- Polygraph examination statement of consent armycom form
- Da form 11 2
- Da form emergency
- Dd 1172 1 form
- Af form 1024
- Navmc 631a pdf form
- Fort benning weapons registration form
- Dod forms website
- Da form 2624
- 5112 1 form
- Us dod form dod bnavpersb 1910 31 us federal forms
- 672 professions form printable
- Dd 884 form
- Form 1911
- 11 r form
- Print blank dd214 form
- Ngr 600 200 biographical sketch form
- Us army letter headed paper form